Kullanıcıları istekleri çeşitlendikçe ve arttıkça paralel olarak uygulamalarda daha karmaşık hale gelirken, database seviyesinde yapılan işlemlerin karmaşıklığı da doğru orantılı takip etmiştir. Bu kompleks yapıları sadeleştirmek için View , common table expression yapılarını kullanmaktayız. İşte bu yazıda Indexed View’a göz atıyor olacağız.
SQL Server da View kullanımı birçok noktada kompleks sorgularımızı gruplamak için kullandığımız bir yapıdır. View’lar aracılığıyla sorgularımızı daha sade ve okunabilir hale getirebiliriz. Ancak bu düzenleme sadece kodu okuyan geliştirmecilere bir avantaj sağlar. Query Optimiser için bir anlamı yoktur.
Yazımızın konusu olan Indexed View burada devreye giriyor. Standart View’ımıza bir Clustered Index ekleyerek performans kazancı açısından nelerin değiştiğini kolaylıkla görebiliriz. Örneğimiz üzerinden inceleyeceğiz.
Önce genel kuralları konuşalım;
Artılar;
- Önemli sorgulama performansı artışı.
Eksiler;
- Indexed View altındaki tablolar üzerinde Data modifikasyonları yaptığımızda, bu değişiklik Indexed View’ımızın Index’ine de yansıyacaktır. Bu da bizim için göreceli olarak yazma performansında düşüş demektir.
- Cross Database tabloları birleştirerek Indexed View oluşturamayız.
- İlk indeximiz Unique Clustered Index olmak zorundadır. Daha sonra farklı Index’ler ekleyebiliriz.
- Schema Binding yapıdan dolayı View içerisindeki ana tabloları Modifiye edemeyiz.
- Indexed View içerisindeki datalar deterministic olmalıdır.(Sorgu aynı kriterlerle her çekildiğinde aynı datayı getirmelidir. Bu sebeple GETDATE(),MAX(),MIN(),COUNT() gibi fonksiyonları Indexed View içinde kullanamayız.)
Adventure Works veritabanında siparişleri yıl, kişi bazında gruplayan bir sorgum var.
SELECT YEAR(Sh.OrderDate) OrderYear,
P.FirstName ,
P.LastName ,
Sh.[Status] ,
SUM(Sd.OrderQty) Qty
FROM Sales.SalesOrderHeader Sh
INNER JOIN Sales.SalesOrderDetail Sd ON Sh.SalesOrderID = Sd.SalesOrderID
INNER JOIN Sales.Customer C ON Sh.CustomerID = C.CustomerID
INNER JOIN Person.Person P ON P.BusinessEntityID = C.PersonID
GROUP BY YEAR(Sh.OrderDate),P.FirstName ,P.LastName ,Sh.[Status]
Bu sorguyu veritabanında farklı yerlerde tekrar tekrar kullanmam gerektiği için bir View oluşturuyorum.
CREATE VIEW vwOrdersByNameYear
AS
SELECT YEAR(Sh.OrderDate) OrderYear,
P.FirstName ,
P.LastName ,
Sh.[Status] ,
SUM(Sd.OrderQty) Qty
FROM Sales.SalesOrderHeader Sh
INNER JOIN Sales.SalesOrderDetail Sd ON Sh.SalesOrderID = Sd.SalesOrderID
INNER JOIN Sales.Customer C ON Sh.CustomerID = C.CustomerID
INNER JOIN Person.Person P ON P.BusinessEntityID = C.PersonID
GROUP BY YEAR(Sh.OrderDate),P.FirstName ,P.LastName ,Sh.[Status]
Bu View dan data çektiğimde ;
SELECT * FROM vwOrdersByNameYear
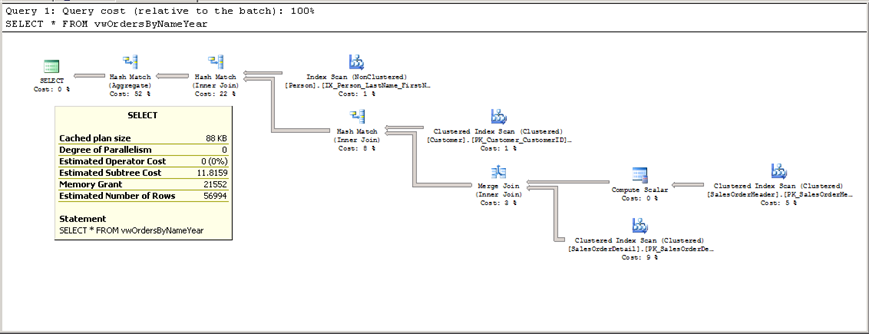
Resim-1
Bu sorgu için sorgu toplam maliyeti 11.8159 olarak hesapladı.(Resim-1)
Şimdi bu View’a index eklemek istesek New Index seçeneğinin pasif olduğunu göreceğiz (Resim-2), peki neden?
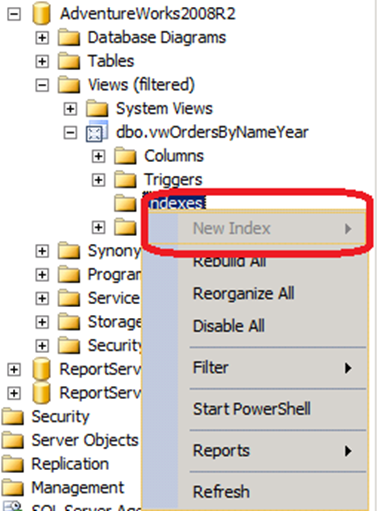
Resim-2
Yazının başında değindiğimiz Schema Binding yapıya ihtiyacımız var. Schema Binging nedir diyenler için; bu Keyword View, Function, SP gibi objeler oluştururken bunlar içinde kullandığımız diğer nesneleri koruma altına almaya yarar. View’ımı Schema Binding olarak oluşturduğumda View’da kullandığım tablolarda DDL operasyonu yapmak isteyen kullanıcılar Schema Binding uyarısı alıp işleme devam edemeyecekler.
View’ı Alter edelim;
ALTER VIEW vwOrdersByNameYear
WITH SCHEMABINDING
AS
SELECT YEAR(Sh.OrderDate) OrderYear,
P.FirstName ,
P.LastName ,
Sh.[Status] ,
SUM(Sd.OrderQty) Qty
FROM Sales.SalesOrderHeader Sh
INNER JOIN Sales.SalesOrderDetail Sd ON Sh.SalesOrderID = Sd.SalesOrderID
INNER JOIN Sales.Customer C ON Sh.CustomerID = C.CustomerID
INNER JOIN Person.Person P ON P.BusinessEntityID = C.PersonID
GROUP BY YEAR(Sh.OrderDate),P.FirstName ,P.LastName ,Sh.[Status]
Indexi eklemek için kodumuzu çalıştıralım;
CREATE UNIQUE CLUSTERED INDEX vwOrdersByNameYear ON dbo.vwOrdersByNameYear(OrderYear, FirstName, LastName,[Status])
Kodunu çalıştırdığımda;
Cannot create index on View ‘AdventureWorks2008R2.dbo.vwOrdersByNameYear’ because its select list does not include a proper use of COUNT_BIG. Consider adding COUNT_BIG(*) to select list.
Hatası alıyorum, bu hatayı Indexed View’da başka bir noktaya değinmek için özellikle aldık. Indexed View’ımızda GROUP BY kullandığımız için COUNT_BIG(*) kullanmak zorundayız.
Bu zorunlu alanı ekleyip işlemimize devam edebiliriz.
ALTER VIEW vwOrdersByNameYear
WITH SCHEMABINDING
AS
SELECT YEAR(Sh.OrderDate) OrderYear,
P.FirstName ,
P.LastName ,
Sh.[Status] ,
SUM(Sd.OrderQty) Qty,
COUNT_BIG(*) C
FROM Sales.SalesOrderHeader Sh
INNER JOIN Sales.SalesOrderDetail Sd ON Sh.SalesOrderID = Sd.SalesOrderID
INNER JOIN Sales.Customer C ON Sh.CustomerID = C.CustomerID
INNER JOIN Person.Person P ON P.BusinessEntityID = C.PersonID
GROUP BY YEAR(Sh.OrderDate),P.FirstName ,P.LastName ,Sh.[Status]
Index’imizi şimdi oluşturalım;
CREATE UNIQUE CLUSTERED INDEX vwOrdersByNameYear ON dbo.vwOrdersByNameYear(OrderYear, FirstName, LastName,[Status])

Resim-3
Tablomuzu tekrar sorgulayalım.
SELECT * FROM vwOrdersByNameYear
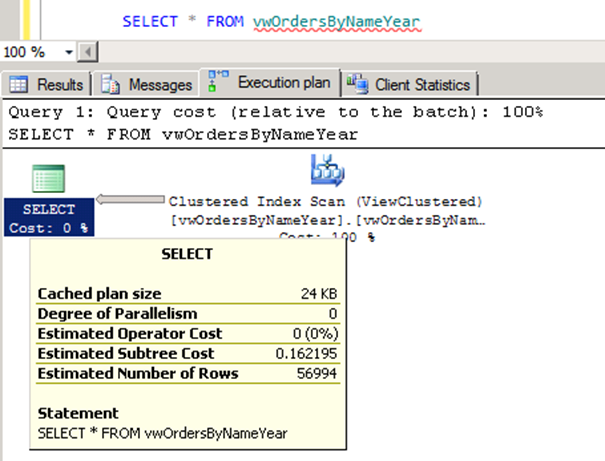
Resim-4
View’ın ilk halinde eriştiğimiz 11.8159 Subtree Cost rakamı 0.162195 e düştü.(Resim-1/Resim-5) Gerçek hayatta göreceğiniz performans kazanımları da (istisnai durumlar haricinde) yüksek oranlarda olacaktır.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar

