Bir uygulamanın performansı kullanıcı deneyiminin en önemli parçalarından biridir. Performanslı uygulama oluşturmanın en önemli parçalarından biri ise şüphesiz ki veritabanına gittiğimiz noktalarda satırlarca veriye hızlı bir şekilde ulaşmaktır. İyi performans göstermeyen SQL sorgularını tespit edip optimizasyonlarını yapmak bunun güzel bir yoludur. Bu yazımda yardımcı araçlar ve birkaç ipucu ile nasıl daha performanslı SQL sorguları yazabiliriz bundan bahsetmek istiyorum. Öyleyse başlayalım .
Öncelikle bir sorgu performansını hangi yöntemler ile ölçebileceğimize bir bakalım.
SET STATISTICS IO / SET STATISTICS TIME
Bir SQL sorgusu; Query, Parse, Optimize, Compile, Execute, Result olmak üzere 6 adımda çalışır. Optimize adımı çalıştırılan sorgunun maliyetinin belirlendiği yani Execution Plan (Query Plan)’ın oluşturulduğu kısımdır. SQL Server, aynı sorgunun birden fazla kez çalıştırılma ihtimaline karşı oluşturduğu execution plan’ı önbelleğe atar. Bu şekilde aynı sorgu için birden fazla derleme işlemi yapılmasının önüne geçilir. Aşağıdaki komutları kullanırken doğru sonuçlar alabilmek için DBCC FREEPROCCACHE ve DBCC DROPCLEANBUFFERS komutlarını kullanarak önbellek temizliği yapmak faydalı olacaktır (ancak bu komutları production’da çalıştırmaktan kaçınmalıyız).
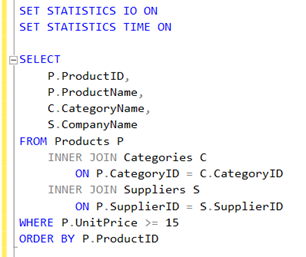
Resim-1
SET STATISTICS IO ON ve SET STATISTICS TIME ON komutları, bize sorgularımızın kullandığı kaynaklar hakkında çeşitli istatistikler sunar. Aşağıdaki basit bir SQL sorgusu ile bu iki komutun bize nasıl bir çıktı verdiğini görelim.
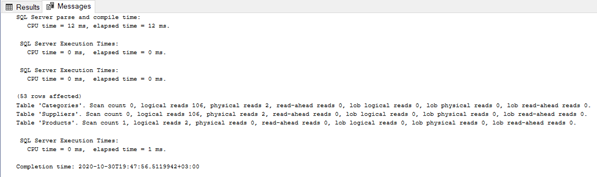
Resim-2
Yukarıda görüldüğü üzere SET STATISTICS TIME ON parse, compile ve execute işlemleri için harcanan CPU süresi ve geçen süre hakkında bize bilgi verir.
SET STATISTICS IO ON ise SQL sorgusu tarafından oluşturulan disk etkinliğinin miktarı hakkında bize bilgi verir.
Scan count: Sorguda kullanılan tablolara erişilme sayısını gösterir.
Logical reads: Veri önbelleğinden (data cache) okunan sayfa sayısına karşılık gelir. Logical reads’in azalması daha az server kaynağının kullanılması anlamına gelir ve performans artışı sağlar. Bir sorgunun performansını değerlendirirken bakacağımız en önemli kısım burasıdır.
Physical reads: Diskten okunan sayfa sayısını gösterir. Physical reads sayısı doğrudan server’ın RAM miktarı ile bağlantılı olduğundan SQL sorgu optimizyonu yaparak bunu azaltamayız.
Read-ahead reads: Sorgu için önbelleğe yerleştirilen sayfa sayısıdır.
EXECUTION PLAN
Execution plan, ihtiyacımız olan verilere erişmenin en verimlini yolunu belirlemek için sorguyu analiz eder. Bir sorgu çalıştırıldığında hangi tablolara nasıl erişildiğini ve sorgu bitimine kadar meydana gelen bütün işlemleri ve bunların maliyetlerini gösterir. Execution Plan sayesinde yüksek maliyetli işlemleri bulabiliriz ve daha sonra bunların iyileştirilmesi için çalışmalar yapabiliriz.
Include Action Execution Plan’ı aktif hale getirerek sorgumuza ait Execution Plan’ı oluşturabiliriz.

Resim-3
Örnek olarak yukarıdaki sorgumuz için bir Execution Plan oluşturalım.
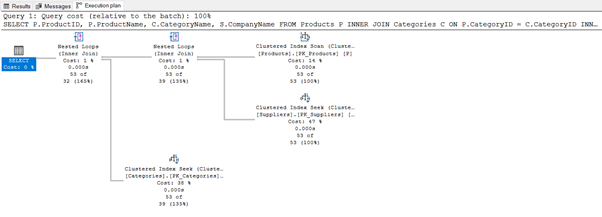
Resim-4
Bir sorgunun performansını nasıl ölçebileceğimizden bahsettikten sonra artık nasıl daha performanslı sorgular yazabileceğimiz konusuna gelebiliriz.
INDEX KULLANIMI
Doğru index kullanımı ile istenilen veriye hedef tablonun tamamını okumaya gerek kalmadan daha kısa bir sürede ulaşabiliriz. Index kavramı oldukça detaylı bir konu ve farklı kullanımları olmakla birlikte bir sorgu performansına nasıl etki ettiğini bir örnek ile göstermek istiyorum.
Primary Key’i BusinessEntityID olarak belirlenen Person tablosunu ele alalım.
![]()
Resim-5
Clustered, Türkçe’de kümelenmiş, sıralanmış anlamına gelir. Yani Clustered Index’e sahip bir tablonun satırları fiziksel olarak sıralanmış olur. Bir tabloda Primary Key olarak belirlediğimiz kolon aslında bir Clustered Index’tir ve her tabloda sadece 1 tane bulunabilir.
Tablomuz için aşağıdaki sorguyu çalıştıralım.

Resim-6
Bu sorguya ait Execution Plan’ı incelediğimizde Clustered Index Scan yapıldığını ve aslında tablonun bütün satırlarının okunduğunu görüyoruz.
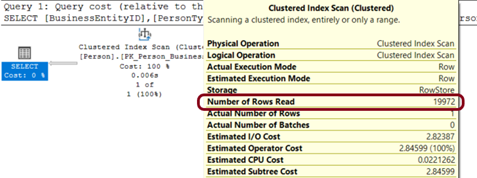
Resim-7
![]()
İstatistiklere baktığımızda ise logical reads’in ne kadar yüksek olduğunu görebiliriz.
Şimdi bu sorguyu iyileştirmek için FirstName ve LastName kolonlarını içeren bir Non-Clustered Index oluşturalım. Non-Clustered Türkçe’de kümelememiş, sıralanmamış anlamına gelir. Non-Clustered Index ile verinin kendisine değil, verinin bulunduğu adrese ulaşılır. Yani pointer görevi görür. Ayrıca bir tablo birden fazla Non-Clustered Index’e sahip olabilir.
![]()
Resim-8
Sorgumuzu tekrar çalıştırıp Execution Plan’ı tekrar incelediğimizde okunan satır sayısının 1’e düştüğünü;
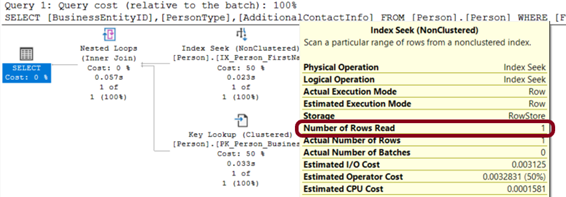
Resim-9
istatistiklere baktığımızda ise logical reads’te oldukça büyük bir düşüş olduğunu görebiliriz.
![]()
Resim-10
TEMP TABLE KULLANIMI
Elimizde çok sayıda kayda sahip bir tablo olduğunu ve bu tablonun bir store procedure içinde birden fazla yerde join işlemine tabi tutulduğunu varsayalım. Bu store procedure her çalıştığında aynı tabloyu birden fazla kez çağırmak oldukça maliyetli olacaktır. Bunun yerine bu tablonun ihtiyaç duyduğumuz kısımlarını temp table’a atmak ve ilgili yerlere bu tabloyu joinlemek sorgu performansına olumlu yönde etki yapacaktır.
Yine oldukça fazla kayıt döndüren bir SQL sorgusunu başka bir sorgu içinde subquery olarak kullanmak yerine bu sorguyu temp table’a atmak ve ilgili yerde joinlemek performans artışı sağlayacaktır.
Temp table kullanımı performans iyileştirmelerinde oldukça yaygın bir yöntem olsa da yanlış kullanım performans problemlerine yol açabilir. Temp table oluştururken öncelikle kendimize “Temp table’a gerçekten ihtiyacımız var mı?” ve “Bu temp table’ı dolduran sorguyu doğru şekilde sınırlandırdık mı?” sorularını sormakta fayda vardır.
Örnek olarak aşağıdaki sorguyu ele alalım.

Resim-11
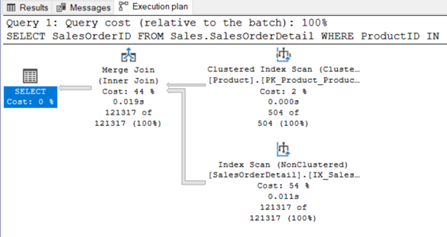
![]()
Resim-12
Sorgumuzun Execution plan’ı yukarıdaki gibidir. Şimdi sorguda subquery içinde çektiğimiz ProductId’leri bir temp table’a atmayı deneyelim.

Resim-13
Ve bu temp table’ı sorugumuza joinleyelim ve sorgumuzu yeniden çalıştıralım.
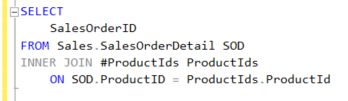
Resim-14
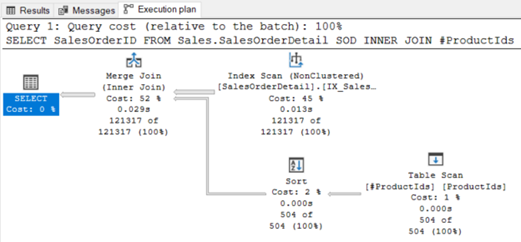
Resim-15
![]() Yeni sorgumuzun Execution Plan’ını ve istatikstiklerini incelediğimizde costların azaldığını ve Product tablosuna ait logical reads’in 15’ten 1’e düştüğünü görebilmekteyiz.
Yeni sorgumuzun Execution Plan’ını ve istatikstiklerini incelediğimizde costların azaldığını ve Product tablosuna ait logical reads’in 15’ten 1’e düştüğünü görebilmekteyiz.
Resim-16
SELECT * FROM’ DAN KAÇINMAK
Sadece belirli kolonlarına ihtiyaç duyduğumuz bir tablodan SELECT * FROM ile bütün kolonları çekmek performansı olumsuz yönde etkileyecektir. Bu yüzden bir SQL sorgusunu optimize ederken ihtiyaçları doğru analiz ederek gereksiz kolonları elemek performans artışı sağlar.
![]()
![]()
Resim-17
Örnek olarak ihtiyacımız olan kolon yalnızca ProductID ise yukarıdaki sorguyu kullanmak bize ekstra maliyet getirecektir. Bunun yerine sadece ProductID’yi çekmeliyiz.
![]()
Resim-18
![]()
Resim-19
UYGUN VERİ TİPİ KULLANMAK
Database’de bir tablo oluştururken dikkat etmemiz gereken en önemli noktalardan biri her sütun için uygun veri tipi seçmektir. Bu sayede verilerimiz diskte daha az yer kaplar ve sorgularımız daha kısa sürede tamamlanır.
Örnek olarak SQL Server’da string veri türüne karşılık gelen Char, Varchar, Nchar ve Nvarchar veri tiplerini verebiliriz.
Sistem, veri tipini Char(x) olarak belirlediğimiz bir sütun için hafızada x karakterlik yer ayırır. Bu veri tipini Varchar(x) olarak belirlediğimizde sistem hafızada girilen verinin boyutu kadar yer ayırır. Yani Varchar’ın daha performanslı olduğunu söyleyebiliriz.
Nchar ve Nvarchar veri tipleri ise uluslararası karakterleri saklamak için kullanılan veri tipleridir. Aynı şekilde Nchar(x) olarak belirlenen sütun için hafızada x karakterlik yer ayırır. Nvarchar(x) olarak belirlediğimizde ise hafızada girilen verinin boyutu kadar yer ayrılır. Her karakter 1 byte olduğundan dolayı char ve varchar olarak belirlediğimiz bir sütuna en fazla 8000 karakter girebiliriz. Çünkü SQL Server verileri 8 KB’lık page’ler halinde saklar.
Nchar ve Nvarchar olarak belirlediğimiz bir sütuna en fazla 4000 karakter girebiliriz. Buradan anlaşıldığı üzere Nchar ve Nvarchar, Char ve Varchar’a göre iki kat fazla yer tutar. Bu sebeple unicode karakterlere ihtiyaç duymuyorsak Nchar ve Nvarchar kullanmamakta fayda vardır.
JOIN / SUBQUERY KULLANIMI
Bu konuda farklı görüşler mecvut olsa da performans açısından iki kullanımın da öne çıktığı durumlar olabilmektedir. Kullanılan tabloların büyüklüğü, indexler, kullanılan platform gibi faktörler sonuçlarımızı etkileyebilir. Hangisini kullanacağımıza karar veremediğimiz durumlarda iki kullanımı da denemek ve performans karşılaştırması yapmak daha doğru bir yol olacaktır.

Resim-20
Örnek olarak aşağıda Left Join ile oluşturduğum sorguyu çalıştıralım ve sonuçlara bakalım.
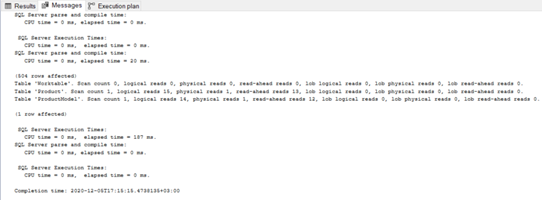
Resim-21
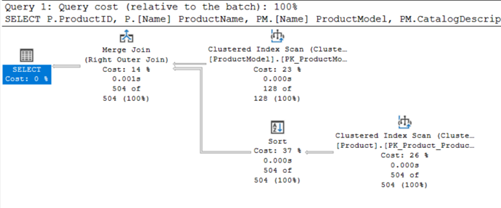
Resim-22
Ardından aynı sorguyu bu defa subquery ile oluşturup iki sorgu performansını karşılaştıralım.

Resim-23
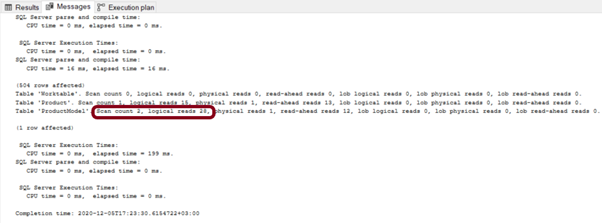
Resim-24
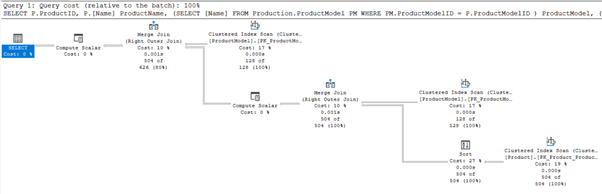
Resim-25
İkinci sorgumuzda ProductModel tablosu için yapılan scan count ve logical reads’in 2 katına çıktığını görebilmekteyiz. Aynı zamanda, yine ikinci sorgu için çıkarılan execution plan ilkine göre daha fazla işlem içermektedir. Yani bizim örneğimiz için join kullanmak subquery kullanımına göre daha performanslıdır.
2. bölümde diğer performans ipuçlarıyla devam edeceğiz.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar
https://www.sqlshack.com/query-optimization-techniques-in-sql-server-the-basics/
TAgs: SQL Sorgu Optimizasyonu Nasıl Yapılır -1

Elinize sağlık güzel bir makale olmuş. Varchar veri türünün Char türüne göre avantajı Page’ler üzerinde daha az yer kaplamasıdır. Varchar bir sutunda veri boyutu dinamik olarak her satır üzerinde doğrulandığı için Index tanımlı bir kolon olacak ise Char veri türüne göre performansı düşük olacaktır.
Yazımda disk boyutunun sorun olabileceği durumu ele aldım. Geri bildiriminiz için çok teşekkür ederim, mutlaka dikkate alacağım :)
Merhaba Büşra hanım,
100 milyon satıra ulaşmış bir tablom var .. Non-clustred oluşturuken veya rebuild yaparken bir zaman zonra hata veriyor ve tamamlayamıyor..
Ne yapılabilir ? Sorun ne olabilir acaba..
şimdiden teşekkür ederim.