SQL Server 2016 Yenilikleri Serimizin ilk iki yazısında InMemory OLTP ve InMemory DW (ColumnStore) alanında duyurulan gelişmelerden bahsetmiştik.
Serinin tüm yazılarına aşağıdaki linklerden ulaşabilirsiniz.
SQL Server 2016 Yenilikleri – In-Memory DW – Updatable ColumnStore Indexes – Bölüm 1
SQL Server 2016 Yenilikleri – In-Memory OLTP Geliştirmeleri – Bölüm 2
SQL Server 2016 Yenilikleri – Operational Analytics – Bölüm 3
Bu yazımızda iki alandaki gelişmeleri bir araya getireceğiz ve gerçek zamanlı analizler yapabildiğimiz ‘Operational Analytics‘ konseptinden bahsedeceğiz.
Önce biraz geçmişe bakalım
Geleneksel bir sistemde Insert, Update, Delete iş yükünü karşılayan Veritabanlarında normalizasyon kuralları uygulanır. I,U,D işlemlerinin optimum kalitede yapılabildiği bu veritabanı modelleri OLTP kısaltmasıyla anılır. Sıklıkla iş süreçlerinin takibi için kullanılan sistemler zamanla çeşitlenir ve farklı mantıklarda tasarlanmış birden fazla OLTP kaynak, yamalanmış sürecin bir parçası olur.
Sonra bu kaynaklardaki veriler iş kararları vermek amacıyla ele alınmak istendiğinde işin içinden çıkılamaz. Çünkü artık kaynaklar arası bir standart kalmamış, veriler kirlenmiştir. Bu durumda devreye veriambarları girer. Veriambarları (DW, DWH) analiz etmeye yani SELECT etmeye en müsait şekilde modellenmiş veritabanlarıdır. Veriler ETL dediğimiz veri aktarım ve dönüştürme süreçlerinden geçirilerek bir takım ara katmanlara, sonrasında da veriambarına aktarılır.
Veriambarlarında verinin kolayca analiz edilebileceği Dimensional Model yaklaşımı benimsenir. Artık elimizdeki sistem birOLAP sistemi olarak anılır. Tabi daha fazla hız ve esneklik bekleyenler için bir adım daha atılır; OLAP Cubelerinin oluşturulması (Multidimensinal, Tabular). En basit söylemle Cubeler veriyi, yapıyı ve ek hesaplamaları üzerinde tutar.Böylece önceden hazırlanmış veriye bir nevi koordinat sistemi mantığıyla erişmek mümkün olur. Tekrar tekrar hesaplama yapılmaz. Bundan sonraki aşamada da veri bir takım raporlama araçlarıyla görüntülenebilir.
Bahsettiğimiz bu geleneksel sürecin avantajları olduğu gibi dezavantajları da var. Bu dezavantajlara kısaca değinelim:
ETL İşlemlerinin yükü:
Öncelikle verileri temizlemek ve standartlaştırmak için ETL işlemleri yapmanız gerekir. Bu işlemler bazen çok karmaşık olabilir. Bunun yanında sisteme girilen verinin raporlanması için belli bir süre geçmesi gerekir. Bazen bu gecikme dakikalar seviyende, bazen de günler seviyesinde olabilir.
Küplerin ‘Process’ edilmesi:
Kaynaklardan veriambarına yapılan aktarımlar ETL süreçlerinde ele alınır. ETL süreçlerine benzer şekilde veriambarından ‘OLAP Cube’lerine de veri aktarımı yapılır. Bu sürece Cube Processing denir. Benzer şekilde burada da bir karmaşıklık ve gecikme söz konusudur.
Yazılım, Donanım, Geliştirme ve Bakım planı:
Sistemdeki karmaşıklık hem geliştirme hem de bakım planının ciddi şekilde ele alınmasını gerektirir. Verinin çeşitli kademelere aktarılması ve çoğaltılması yazılım/donanım yatırımı konusunda titiz olmayı gerektirir.
Özetlersek; geleneksel analitik sistemlerde veri çoklanır ve verinin gelmesi için zamana ihtiyaç vardır. Maliyetli ve yavaş (en azından gerçek zamanlı sayılmaz) bir sistem.
Tabi ki, eğer birden fazla kaynak varsa, bunları bir araya getirmek için veriambarı tasarlamak çoğu zaman en sağlıklı ve en güvenli yol olur. Bazen bu adım atılmadan sistemde performans artışı sağlanamayabilir.
Index, paralelizm vb. konfigurasyonların yetmediği yerlerde okuma ve yazma iş yüklerini ayırmak genellik net çözümdür.
Veriambarı zorunluluğunun olduğu sistemlerde gerçek zamana yakın bir raporlama yapmak için veriambarından raporlama yapılır. OLAP Cube’lerinin avantajlarından faydalanmak isteniyorsa, Multimensional için sadece yapının korunduğu, verinin veriambarından her defasında temin edildiği ROLAP modu, Tabular için benzer şekilde verinin veriambarından temin edildiği DirectQuery modu tercih edilir. Böylece yapı her ne kadar OLAP Cube olsa da veri veriambarının performansına ve güncelliğine bağlı olarak sunulur. Geleneksel sistemlerin gerçek zamanlı raporlama konusunda geldiği nokta özetle buydu.
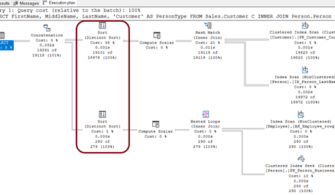
Resim-1
Oyuna sonradan dahil olan çözümlerle düşünelim
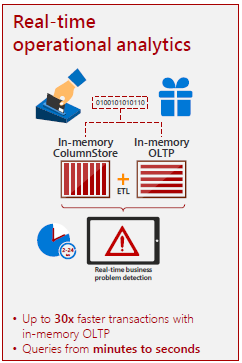
SQL Server 2012 ile duyurulan ‘ColumnStore Index’ler zamanla gelişti ve Select konusunda 100 kat performans sunan InMemory DW çözümü, SQL Server 2016 ile birlikte son derece başarılı bir noktaya ulaştı. Benzer şekilde SQL Server 2014 ile birlikte duyurulan InMemory OLTP‘de ‘Memory Optimized Table‘lar üzerinden INSERT, UPDATE, DELETE konusunda 30 kat’a varan performans sunabildi ve geliştirilerek SQL Server 2016 ile birlikte bir çok prangadan kurtuldu.
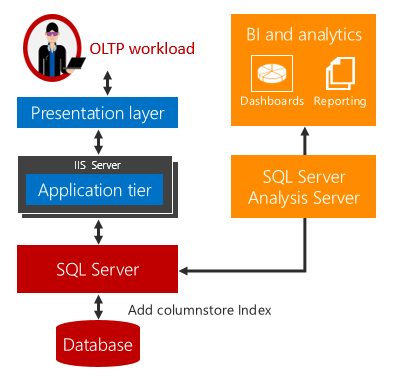
Artık Disk Based bir tablo ve/veya Memory Optimized bir tablo üzerinde RowStore veya ColumnStore index kullanmak mümkün. Bu indexleri belli şartlar altında çeşitli kombinasyonlarda kullanarak hem yazma iş yükünü hem de okuma iş yükünü aynı tabloda toplayabiliriz. Bu durum yüksek performansın sonucu olan gerçek zamanlı raporlama yapmaya imkanverir. Artık raporlarınızı ister bu tablodan isterseniz direk tabloya erişimle veri getirecek şekilde konfigure edilmiş OLAP Cubelerden gerçek zamanlı olarak elde edebilirsiniz. Böylece bir takım senaryolar için ETL ve DW süreçlerine ihtiyacınız kalmaz. Veri doğrudan gerçek zamanlı olarak kaynaktan temin edilir.
Resim-2
Nasıl yapılır?
1. Operasyonel işlemlerin yüklendiği tablo RowStore veya Memory Optimized olabilir.
- INSERT, UPDATE, DELETE performansını arttıracak bir çok ipucu var. Mesela BTree indexleri kaldırabilirsin (bunun yerine ColumnStore tavsiye edilir.), constrainleri kapatabilirsin, flagler kullanabilirsiniz vs.
- Memory Optimized tablolar IUD işlemlerinde 30 kat performans sunar. Kısıtlar göz önünde bulundurularak bu tür tablolar tercih edilebilir.
2. Yavaş değişen (Warm) veriler için filtrelenmiş (Where koşulu ile belli şarttaki verilerin indexlendiği) Nonclustered ColumnStore indexler tanımlanabilir (Şimdilik Memory Optimized tabloda filtreleme özelliği kullanılamıyor).
- Mesela girilen siparişlerden sadece teslimat bekleyenleri filtrelemek isteyebilirsiniz. Sadece ihtiyacınız olan aralık indexlenmiş olur. Böylece fragmantasyonu en aza indirmiş olursunuz. Daha az veri yazıldığı için yazma performansına olan negatif etki en aza iner.
- İhtiyaç duyulan diğer noktalar için de RowStore indexler kullanım amacı ve yetenekleri göz önünde bulundurularak tanımlanabilir.
3. Çok sık güncellenen kısım için (Hot) Btree index, daha az güncellenen (Warm) veya neredeyse hiç güncellenmeyen kısım için (Cold) (Daha çok okuma yapılan) ColumnStore index tanımlanabilir.
- Burada asıl mesele doğru indexi fazla yük getirmeyecek şekilde doğru aralık için kullanmaktır. Tabi ek olarak Query Optimizer da en verimli yolu tercih edecektir.
- ColumnStore indexlerdeki fragmantasyonu azaltmak için COMPRESSION_DELAY ifadesi ile sıkıştırma işlemini dakika cinsinden geciktirmek mümkün. Böylece her 1 milyon satır için sıkıştırma işlemi yapmak yerine, istenen aralıklarda buna vakit ayrılabilir.
Bir sipariş sistemini düşünürsek:
- Alınan siparişler – Çok sık veri girişi olur (Hot Data) – Memory Optimized tablo önerilir.
- Teslimatı bekleyenler – Zaman zaman durumlarında değişiklik olur (Warm Data) – Filtrelenmiş NonClustered indexler önerilir.
- Teslim Edilmiş Siparişler – Neredeyse hiç değişiklik olmaz (Cold Data) – Filtrelenmiş ColumnStore önerilir.
Özetlemek gerekirse;
Senaryonun gereklilikleri göz önde bulundurularak, InMemory OLTP, InMemory DW ve geleneksel performans arttırıcı yöntemler bir araya getirilirse maksimum yazma ve maksimum okuma avantajı elde edilebilir. Böylece ETL ve DW süreçlerine gerek kalmadan yazma ve okuma iş yükünü üstlenebilen bir tablo üzerinden gerçek zamanlı raporlama yapmak mümkün olur.
SQL Server 2016 ile birlikte çok gelişmiş araçlar elimizde olacak. Bunları doğru şekilde bir araya getirdiğimizde etkileyici kazanımlar elde edeceğimiz aşikar.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar