
SQL Server 2019 ile gelen yenilikleri anlatmaya devam ediyoruz. Bu yazıda Memory Grant Feedback özelliğinden bahsedip demo yapacağız. Bu özellik SQL Server 2019’un Intelligent Query Processing (Akıllı Sorgu İşleme) adı altındaki özelliklerden biridir.
SQL Server için bellek kullanımı çok önemlidir. Özellikle sorgularımızın performanslı çalışması için bellek kullanımından yararlanmak isteriz. Bu noktada karşımıza In-Memory ve Columnstore Index kavramları çıkmaktadır. SQL Server 2017’de In-Memory tablolarda ColumnStore Indexler oluşturup belleğin gücünü ve sorgu performanslarına olan olumlu etkilerini biliyoruz. SQL Server 2019’da ise Memory Grant Feedback özelliği ile aynı etkiye sahip bir çalışma sistemi ortaya çıkmaktadır. Çalıştırdığımız bir sorgunun ilk çağırmada bellek kullanımı hesaplanır. Ardından tekrarlanan çağırımlarda execution plan ve bellek o sorguya özel ayrılır. Sorgu daha sonraki her çağırmada herhangi bir hesaplama işlemi olmadan hızlıca bellekte kaydedilen execution plandan çağırılır. Bu özellik bellek kullanımını öğrenmek ve bellek desteğini kullanmayı amaçlamaktadır. Sorgulardaki yanlış bellek tahminlemesini ortadan kaldırır. Bu özelliği kullanmak için veritabanımızın Compatibility Level 150 (SQL Server 2019) olması yeterlidir.
Şimdi bu özellikle ilgili bir demo yapalım.
Öncelikle bu uygulamada veritabanı olarak Microsoft’un WideWorldImportersDW isimli test veritabanını kullanacağım. İlgili veritabanına buradan ulaşabilirsiniz.
Veritabanını restore ettikten sonra aşağıdaki script ile çalışma yapacağım tabloyu büyütüyorum.
IF DB_NAME() != 'WideWorldImportersDW'
USE WideWorldImportersDW
SET NOCOUNT ON
GO
IF OBJECT_ID('Fact.OrderHistory') IS NULL
BEGIN
SELECT [Order Key], [City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key]
INTO Fact.OrderHistory
FROM Fact.[Order];
END;
ALTER TABLE Fact.OrderHistory
ADD CONSTRAINT PK_Fact_OrderHistory PRIMARY KEY NONCLUSTERED ([Order Key] ASC, [Order Date Key] ASC) WITH (DATA_COMPRESSION = PAGE);
GO
CREATE INDEX IX_Stock_Item_Key
ON Fact.OrderHistory ([Stock Item Key])
INCLUDE(Quantity)
WITH (DATA_COMPRESSION = PAGE);
GO
CREATE INDEX IX_OrderHistory_Quantity
ON Fact.OrderHistory ([Quantity])
INCLUDE([Order Key])
WITH (DATA_COMPRESSION = PAGE);
GO
CREATE INDEX IX_OrderHistory_CustomerKey
ON Fact.OrderHistory([Customer Key])
INCLUDE ([Total Including Tax])
WITH (DATA_COMPRESSION = PAGE);
GO
IF (SELECT COUNT(*) FROM [Fact].[OrderHistory]) < 3702592
BEGIN
DECLARE @i smallint
SET @i = 0
WHILE @i < 4
BEGIN
INSERT INTO [Fact].[OrderHistory] ([City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key])
SELECT [City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key]
FROM [Fact].[OrderHistory];
SET @i = @i +1
END;
END
GO
IF OBJECT_ID('Fact.OrderHistoryExtended') IS NULL
BEGIN
SELECT [Order Key], [City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key]
INTO Fact.OrderHistoryExtended
FROM Fact.[OrderHistory];
END;
ALTER TABLE Fact.OrderHistoryExtended
ADD CONSTRAINT PK_Fact_OrderHistoryExtended PRIMARY KEY NONCLUSTERED ([Order Key] ASC, [Order Date Key] ASC)
WITH (DATA_COMPRESSION = PAGE);
GO
CREATE INDEX IX_Stock_Item_Key
ON Fact.OrderHistoryExtended ([Stock Item Key])
INCLUDE (Quantity);
GO
IF (SELECT COUNT(*) FROM [Fact].[OrderHistory]) < 29620736
BEGIN
DECLARE @i smallint
SET @i = 0
WHILE @i < 3
BEGIN
INSERT Fact.OrderHistoryExtended([City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key])
SELECT [City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key]
FROM Fact.OrderHistoryExtended;
SET @i = @i +1
END;
END
GOBu transaction işlemi log file büyüteceği için küçültmekte fayda var. Aşağıdaki script ile log truncate ediyoruz.
CHECKPOINT GO DBCC SHRINKFILE (N'WWI_Log' , 0, TRUNCATEONLY) GO
Şimdi sorgumu çalıştıracağım. Öncesinde Compatibility Level ayarını yapıp, plan cache temizliği yapıyorum.
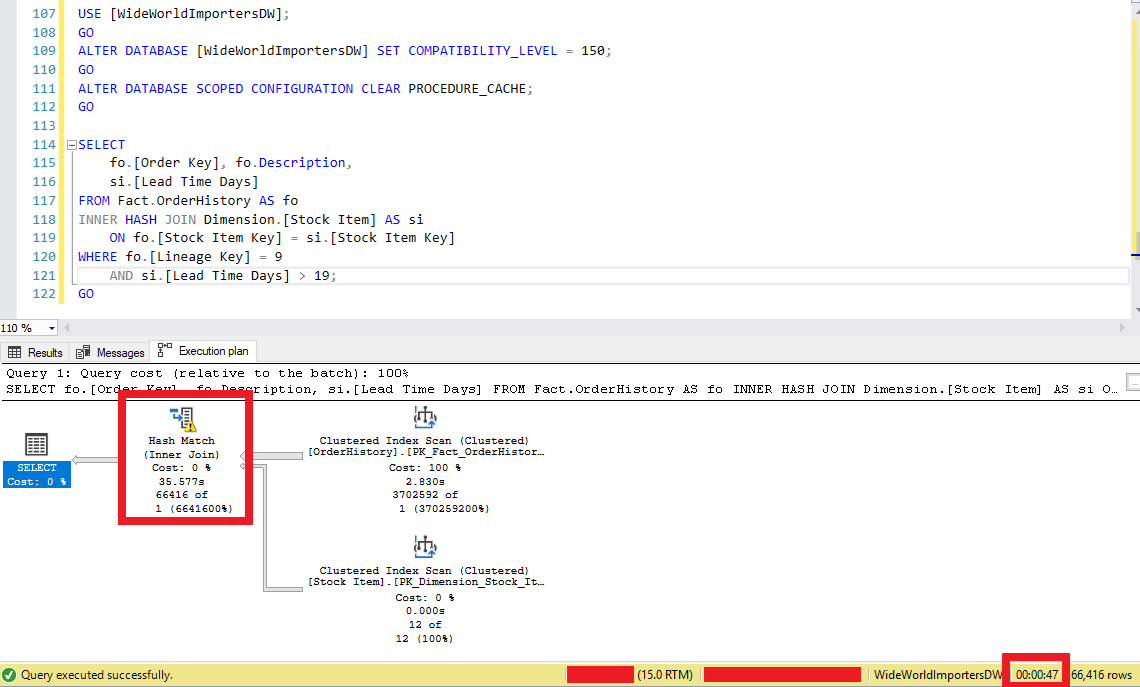 Resim – 1
Resim – 1
Sorgu 47 saniyede sonuç dönmüş ve Resim-2’de görüldüğü gibi Hash Match işlemi üzerinde bir uyarı görmekteyiz. Burada bu sorguyu çalıştırmak için memory kullanımının yetersiz olduğu ve tempdb spillerinin kullanıldığı bahsedilmektedir. Bu aslında çok görmek istemediğimiz bir durumdur. Veritabanı kaynaklarında I/O problemi olduğunu ifade etmektedir.
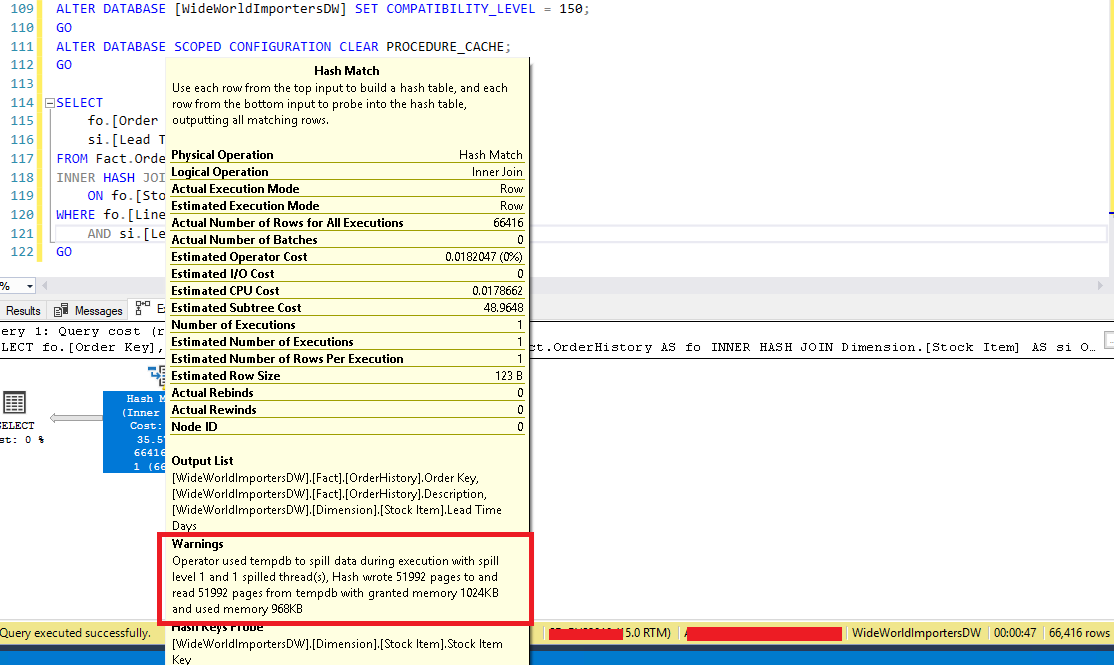 Resim – 2
Resim – 2
Select nesnesi üzerine gelip Properties dediğimizde tüm planın özelliklerine bakılmaktadır. Resim-3‘de gösterilen MemoryGrantInfo bölümünü açtığımızda GrantedMemory‘nin 1056 (1MB) olduğunu ve IsMemoryGrantFeedbackAdjusted seçeneği yanında NoFirstExecution yazısını görmekteyiz. Bu sorgunun ilk kez çalıştırıldığını ifade etmekte ve bu sorgu için 1056 KB‘lik bir bellek ayrıldığını göstermektedir.
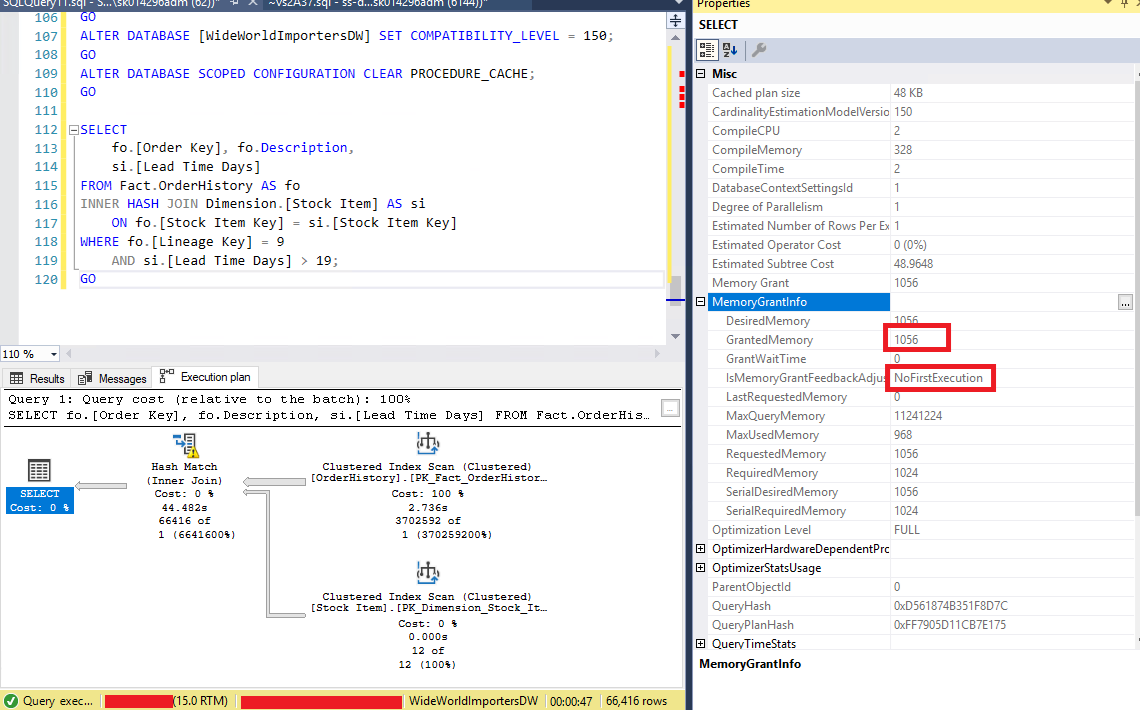 Resim – 3
Resim – 3
Sorgumu tekrar çalıştırıyorum. Bu sefer 6 saniyede sonuç döndüğünü ve Hash Match üzerindeki uyarının kalktığını görmekteyiz.
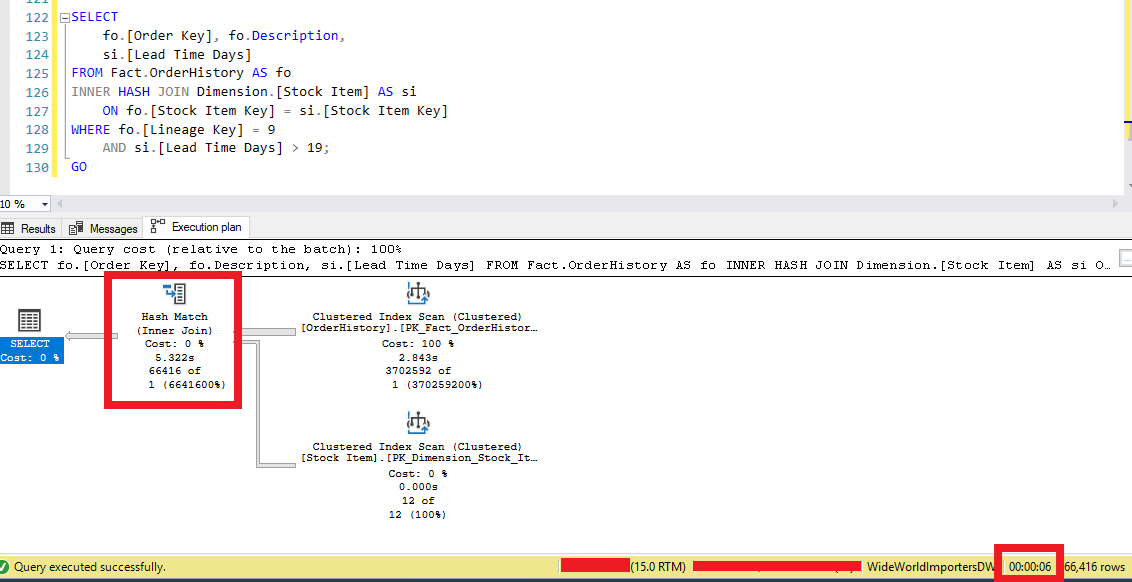 Resim – 4
Resim – 4
Yine execution plan özelliklerinde aynı alana baktığımızıda bu sefer GrantedMemory kısmının 624976 (625 MB) olduğunu ve IsMemoryGrantFeedbackAdjusted kısmında ise YesAdjusting yazısını görmekteyiz. Bu sorgunun özelliği ayarlamaya çalıştığını ifade etmektedir.
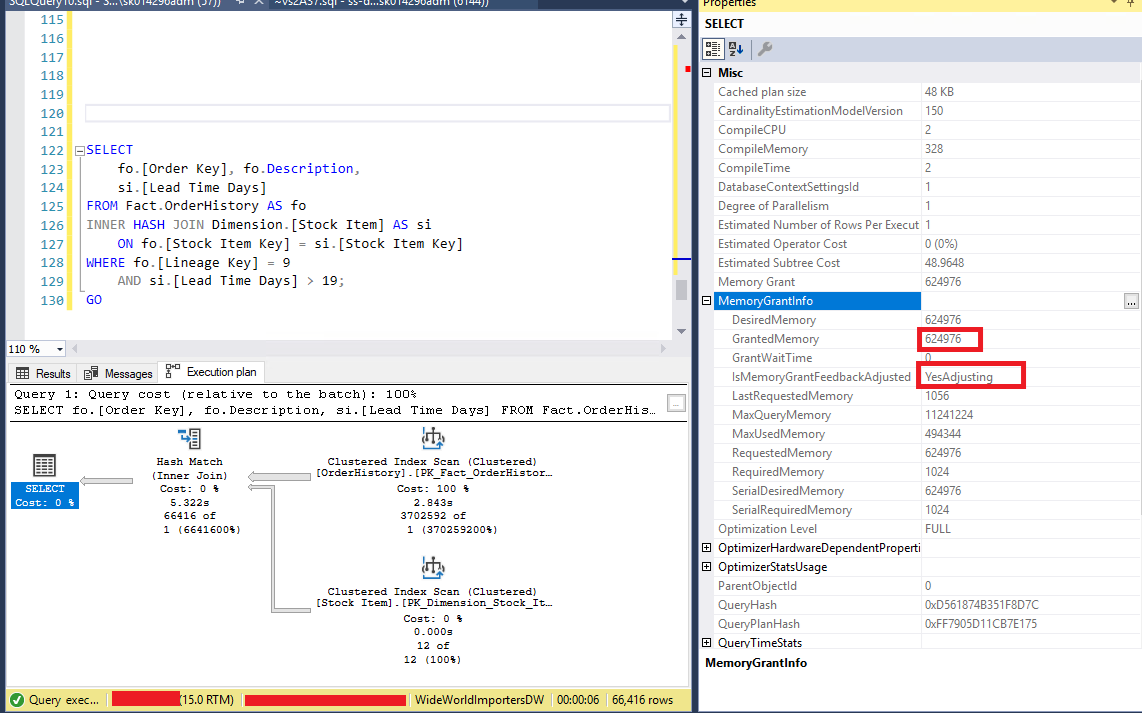 Resim – 5
Resim – 5
Aynı sorguyu bir defa daha çalıştırıyorum. Sorgu sonucu yine 6 saniye sürmektedir. Özellikler kısmına geldiğimde bu sefer IsMemoryGrantFeedbackAdjusted yanında YesStable yazmaktadır. Bu Memory Grant Feedback özelliğinin, sorguyu tamamen bellekte yürütmek için gereken en uygun bellek yardımını bulduğu anlamına gelmektedir. Sonraki her sorgu çalıştırmalarında aynı ifade yer alır ve aynı sürede sonuç dönmektedir.
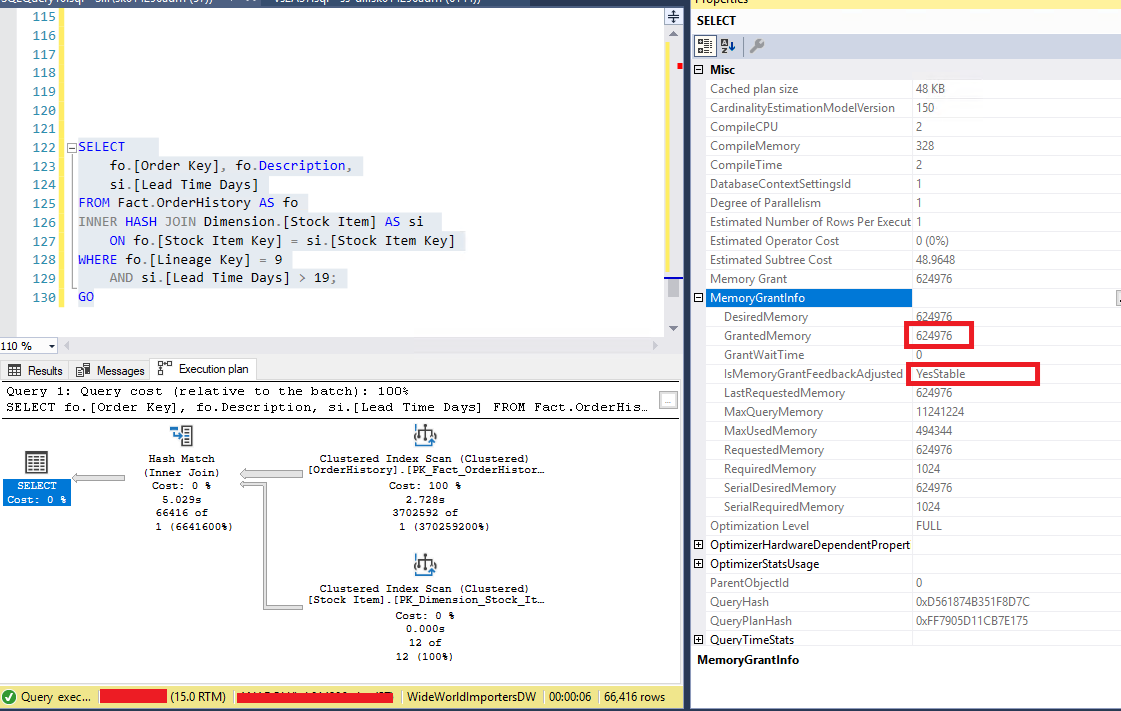 Resim – 6
Resim – 6
Bu yazıda SQL Server 2019’un Intelligent Query Processing (Akıllı Sorgu İşleme) altındaki Memory Grant Feedback özelliğinden bahsettik. Yaptığımız demoda sorgu performansına yaptığı olumlu etkiyi gördük. SQL Server 2019 ile sorgu performanslarında herhangi bir konfügrasyon veya geliştirmeye gerek duymadan bir artış gözlenmektedir. Mevcut yapınız ne olursa olsun
SQL Server 2019’un yeniliklerini anlatmaya devam edeceğiz. Bir sonraki yazıda görüşmek üzere.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar
https://www.mshowto.org
TAGs: SQL Server 2019, SQL Server 2019 yenilikleri, SQL Server 2019 Features, SQL 2019, Memory Grant Feedback, MGF, Query Processing, Intelligent Query Processing, In-Memory, Execution Plan
