Managed Availability – Bölüm 1’de Exchange Team tarafından alınan kararların ve Managed Availability yapısının nasıl planlandığını belirtmiştik. Serimizin bu ikinci bölümünde sizlere Managed Availability ve Bileşenlerini anlatmaya çalışacağım.
Managed Availability ve Bileşenleri
Managed Availability, Exchange 2013 için geliştirilmiş olan kullanıcı odaklı monitoring ve recovery altyapısıdır. Managed Availability üç ana durumu ölçümlemek için tasarlanmıştır. Bu durumlar: Availability yani “erişilebilirlik”, “kullanıcı tecrübesi” ve “hata oluşuyor mu?”
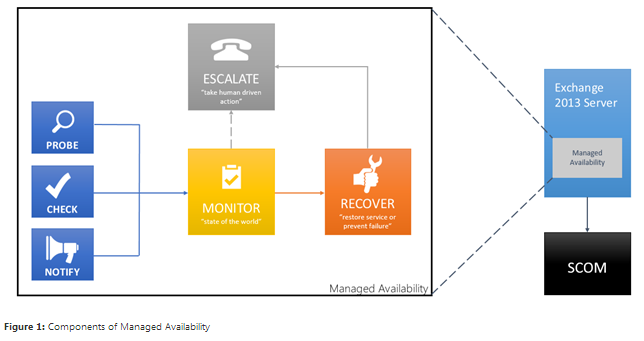
Managed Availability Exchange 2013 içindeki tüm sunucu rollerine inşa edilmiştir. Eşzamanlı olmayan üç temel unsurdan oluşur. İlk bileşen prob engine’dir. Prob engine’in görevi sunucudan ölçümler almaktır. Bu da monitor olan ikinci bileşene geçiş sağlar. Monitor düzgün kabul ettiğimiz iş mantığını kodlar. Bu pattern recognition motoru olarak kabul edilebilir; elde edilen farklı ölçümler arasından farklı yüzeyleri arar ve sonra bunun sağlıklı olup olmadığına karar verir. Son olarak responder motoru vardır; aşağıdaki şemada Recover olarak etiketlenmiştir. Bir şey sağlıksız olduğunda ilk eylem bu bileşeni kurtarma girişimidir. Managed Availability bir çok aşamalı kurtarma eylemi sağlar; ilk deneme application pool’u yeniden başlatmak olmalı, ikinci deneme servisi yeniden başlatmak, üçüncü deneme ise server’ı yeniden başlatmak ve son deneme ise daha fazla trafiği almamak için server’ı kapalı tutmaktır. Eğer bu denemeler başarısız olursa, Managed availability event log ile sorunu bir yöneticilere aktarır.
Bazı şeylerin dağıtılmış olduğunu farkedebilirsiniz. Daha önce SCOM agentlar her sunucudaydı ve tüm ölçümleri merkezi SCOM’da toplanırdı. SCOM tüm gelen ölçümleri değerlendirip başarılı ve başarısız olanları ayırt etmek zorunda kalırdı. Büyük ölçekli ortamlarda karmaşık korelasyonlar yüksek sayılara ulaşabilirdi ve uyarıların çalışması uzun sürebilirdi. Bu nedenle her şeyi tek bir yere toplamak ölçümlemeyi engelleyebiliyordu. Bunun yerine her sunucunun kendi başına davranmasını sağlandı- her sunucu probları kendi çalıştırıyor, görüntülemeyi kendi yapıyor, self-recover kendi yapıyor ve gerekirse sorunu yöneticiye iletiyor.
Probes
Probe altyapısı 3 temel iskeletten oluşur.
- Probe sentetik işlemler üzerine inşa edilmiştir. Geçmiş sürümlerdeki test cmdlt’leri benzer yapıdadırlar. Sentetik uçtan uca kullanıcı işlemlerinin yürütülmesi, Probların hizmet algısı ile ölçümlenir.
- Check’lerin pasif bir izleme mekanizması vardır. Gerçek müşteri trafiğini checkler denetler.
- Uyarı mekanizması Probun çalışmasını beklemeden hemen harekete geçme imkanı sunar. Arıza çıkar çıkmaz harekete geçilmesi bu şekilde sağlanır. Uyarı mekanizması mevcut uyarılara göre ayarlanmıştır. Örneğin sertifikanın süresi bittiğinde uyarı mekanızması tetiklenir ve sertifikanın yenilenme uyarısı çıkar.
Monitors
Problar tarafından toplanan datalar monitorlere aktarılır. Bunun monitor ve problar arasında teke tek bir korelasyon olmasına gerek yoktur, bir çok prob tek bir monitore data aktarır. Monitorler problardaki duruma bakarak sonuca varır. Sonuçlar genelde ikilidir; arızalı ya da değil.
Daha önce belirtildiği gibi Exchange 2013 son kullanıcı deneyimine odaklanmıştır. Bunu gerçekleştirmek için ortamdaki farklı katmanlar monitorlenir.
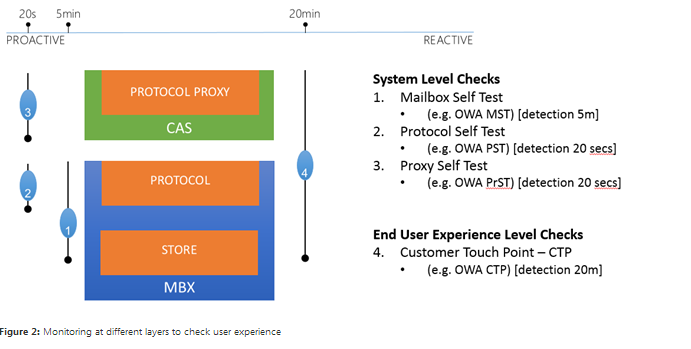
Yukarıdaki şekilde de görüldüğü gibi 4 farklı kontrol bulunur. İlk kontrol mailbox’ın kendi kendini kontrol etmesidir; bu prob yerel protokol veya arabirimin veritabanına erişilebilirliğini denetler. İkinci kontrol protokolun kendi kendini testi olarak bilinir ve lokal protokolün mailbox serverı üzerinde çalışıp çalışmadığını denetler. Üçüncü kontrol proxynin kendi kendini test etmesidir. Proxy’nin protocol üzerinde fonksiyonel çalıştığını doğrular ve bu kontrol Client access server üzerinde çalışır. Dördüncü ve son kontrol her şey dahil kontrolüdür uçtan uca deneyimini denetler. Her kontrol farklı zaman aralıklarında çalışır.
Her dosya ile ayrı başa çıkmak için katman katman monitorleme yapılır. Exchange 2013 te korelasyon motoru olmadığı için her dependency için farklı problara karşılık gelen ve farklı hata kodları ile ayrıştırılır. Örneğin bir mailbox self testin ve protokol self test probunun başarısız olduğu zaman, size ne anlatır? Store’un çalışmadığını mı? Hayır aslında Mailbox server üzerinde local protocol instance’ın çalışmadığını anlatır. Eğer çalışan protocol self-test ile çalışmayan mailbox self test görürseniz size ne anlatır? Bu senaryo storage katmanlarında problem olduğunu ki aslında bu store veya database’in offline olduğunu gösterir.
Bu monitorleme açısından uyarılar üzerinde daha iyi kontrolümüzün olduğu anlamına gelir. Örneğin OWA’nın durumunu değerlendiriyorsak Mailbox self-test’in çalışmadığı, Protocol self-test’in çalıştığı senaryo ortamında alarmı geciktirilir; ancak Mailbox self-test ve protocol self-test monitörleri sorun bildiriyorsa o zaman hata üretilir.
Responders
Responder monitor tarafından oluşturulan uyarılara dayalı yanıtlar yürütür. Monitor arızalı uyarısı vermediği sürece yürütme yapmaz.
Bir kaç çeşit Responder mevcuttur.
- Restart Responder Servisi sonlandırır ve yeniden başlatır.
- Reset AppPool Responder ISS app pool döngüsünü sağlar.
- Failover Responder Exchange 2013 mailbox server’ını servis dışı bırakır.
- Bugcheck Responder Serverda bug kontrolu başlatır.
- Offline Responder Servis dışı olan makinada protokol başlatır.
- Escalate Responder Sorunu iletir.
Specialized Component Responder
Offline Responder, Client Access Server üzerinde kullanılan protokolleri kaldırmak için kullanılır. Bu responder load balancer-agnostic yani load balancer olması ihtimali için tasarlanmıştır. Bu responder çalıştığında protokol, load balancer arızasız kontrolünü tanımayacak, böylece load balancer havuzundan server veya protokol kaldırılarak load balancer etkinleştirir. Aynı şekilde ilgili monitor arızasız uyarısı verdiğinde otomatik olarak başlatma sağlayan ilgili responder için online reponderda vardır. (bağlantılı başka bir arızanın monitörlenmediği varsayılırsa). Online responder basitçe protokol’ün load balancer’a arıza kontrol yapmasına izin verir; buda load balancer’a server ve protokol’ü load balancer havuzuna yeniden eklemesine izin verir. Offline responder Set-ServerComponentState cmdlet ilede başlatılabilir. Bu, adminlerin manüel olarak Client Access Server’ı bakım moduna geçirmelerini sağlar.
Escalate Responder çalıştığında Exchange 2013 Management Pack’in tanıyabileceği Windows event oluşturur. Bu normal bir Exchange olayı değildir. OWA’nın çalışmadığını veya IO problemlerini söyleyen bir olay değildir. Arızalı ya da arızalı değildir sorununu açığa çıkaran bir Exchange olayıdır. SCOM içindeki monitörleri manipule etmek için single instance event kullanır. Bu işlem ürüne yayılmış bir sorun yerine Escalate Responderda oluşturulmuş event’e karşılık yapılır. Bunu bir seviye yönlendirmesi olarak kabul edebiliriz. Managed Availability SCOM içinde monitor açıldığında karar verir. Managed Availability bu kararı sorun artmaya başladığında başka bir deyişle sistem yöneticisi dahil olması gerektiği durumda verir.
Ayrıca tüm servislerin tehlikeye girmemesi için Responder’lara throttling uygulanabilir. Throttling responderın ne olduğuna göre değişir.
- Bazı Responderlar DAG veya load balanced CAS havuzu içindeki serverları minimum sayıda hesaba katarlar.
- Bazı Responderlar çalışma arasındaki süreleri hesaba katarlar.
- Bazı Responderlar başlatılmış responderlar arasındaki sıklığı hesaba katarlar.
- Bazılarıda yukarıda belirtilen kombinasyonların bazılarını kullanırlar.
Respondera bağlı olarak kesinti meydana geldiğinde responder’ın işlemi ertelenebilir ya da tamamen atlanabilir.
Kurtarma sıralaması
Monitorlemenin kesintiye uğrayan responder’ın türünü ve bu kesintinin zaman çizelgesini belirlemesinin çok önemli olduğunu unutmamalıyız, biz bunu Monitor’ün Recovery Sequence yani kurtarma sıralaması olarak adlandırıyoruz. Örneğin OWA protocol (Protokol Self-Test) için prob verisi monitorü hatalı gösterdi. Bu noktada o anki saat kaydedilir. (buna T diyeceğiz) Monitor kurtarma hattı oluşturmaya başlar. Kurtarma hattı içinde belli zaman aralıkları ile monitor’ün kurtarma hareketleri belirlenebilir. Mailbox Server üzerinde OWA protokol monitor’ün recovery sequence yani kurtarma sıralaması:
- T=0 ise, sıfırlama ISS Application pool responder’ı çalıştırılmıştır.
- Eğer T=5 dakika ise monitor ve düzgün çalışıyor durumuna dönmemiş, Failover responder çalıştırılmaya başlar ve database, başka bir servera taşınır.
- Eğer T=8 dakika ise monitor ve düzgün çalışıyor durumuna dönmemiş, Bugcheck responder çalıştırılmaya başlar ve server zorla yeniden başlatılır.
- Eğer T=15 dakika ise monitor hala düzgün çalışıyor durumuna dönmemiş, Escalate responder başlatılmıştır.
Monitor düzgün çalışıyor durumuna döndüğünde recovery sequence hattı durur. Unutmayalım ki son başlatılan işlem bir sonraki başladığında sonlanmış olmak zorunda değildir. Ek olarak bir monitor için birden fazla belirtilmiş zaman sıklığı olabilir.
System Center Operations Manager (SCOM)
System Center Operations Manager (SCOM) Exchange ortamının sağlıklı çalışma bilgilerini gösteren bir portal olarak çalışır. SCOM portalının sağlıksız çalışması durumunda Escalate Responder aracılığı ile Application log’a olaylar yazılır.
- Active Alerts – aktif hatalar
- Organization Health – yapının durumu
- Server Health – server durumu
Exchange Server 2013 SCOM Management pack, SCOM 2007 R2 ve SCOM 2012 tarafından desteklenmektedir.
Exchange Server 2013 SCOM Management Pack’i buradan indirebilirsiniz.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar
