
İlk bölümde bir SQL sorgu performansını hangi yöntemler ile ölçebileceğimizi ve bazı performans ipuçlarını incelemiştik. Bu bölümde diğer ipuçlarından bahsetmek istiyorum.
WHERE vs. INNER JOIN
Bir SQL sorgusunda tablo birleşimi INNER JOIN yerine WHERE cümlesinde tanımlanabilir. Bu tür sorgular ilk önce kartezyen çarpım ile tüm olası seçenekleri oluşturup daha sonra bu seçenekler için WHERE koşulunu uygular. Bu bazı veritabanları için verimsiz olsa da çoğu DBMS ortamında WHERE ile yapılan tablo birleşimleri arka planda INNER JOIN’e dönüştürülür.
Örnek vermek gerekirse;
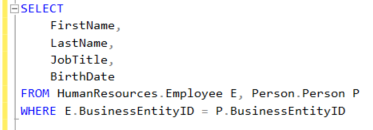

Resim – 1


Resim – 2
SQL Server için yukarıdaki iki sorgunun Execution Plan’ları ve logical reads’i tamamen aynıdır. Yani performans açısından bir farkları yoktur.


Resim – 3
![]()

Resim – 4
Ancak, sorgunun okunabilirliği ve sürdürülebiliriği açısından tablo birleştirmelerini INNER JOIN ile filteleme işlemlerini ise WHERE ile yapmak daha doğru bir tercih olacaktır.
DISTINCT KULLANIMI
DISTINCT, tekrar eden kayıtları elemek için kullanılan bir anahtar sözcüktür. Arka planda sıralama işlemi yaptığından dolayı satırlarca kaydı sıralamak zaman alır. Bu da SQL Server için oldukça fazla iş yükü yarattığından dolayı yalnızca gerçekten ihtiyaç duyduğumuz durumlarda “SELECT DISTINCT” ifadesine başvurmalıyız. Tekrarlı kayıt içermeyen bir sonuç kümesi oluşturmak için DISTINCT kullanımını bir alışkanlık haline getirmek sorgu performansını olumsuz etkileyecektir. Birkaç önemli nokta ile bu durumdan kaçınmak mümkündür.
Eğer sonuç kümemizi oluşturmak için seçtiğimiz sütunlardan herhangi biri unique değer içeriyorsa DISTINCT kullanmamıza gerek yoktur.
Ya da seçtiğimiz her kolonun oluşturduğu kombinasyonlar unique ise yani dönen her satırın birbirinden farklı değerler içerdiğini garanti edebiliyorsak yine DISTINCT kullanmamıza gerek yoktur.
Sorgu içerisinde kullandığımız tabloların doğru oluşturulmaması, yanlış joinleme yapılması gibi durumlar tekrarlı kayıtlara neden olabilir. Böyle durumlarda DISTINCT’e başvurmak yerine sorunun kaynağını aramak daha doğru olacaktır.
Bunu basit bir örnekle özetlemek gerekirse;
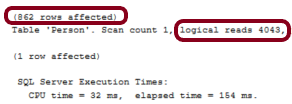
Primary Key’i BusinessEntityID olarak belirlenen ve şu anda başka index’i bulunmayan Person tablosu için aşağıdaki sorguyu çalıştırıp Execution Plan’ı incelediğimizde fazladan bir sıralama maliyeti görüyoruz.
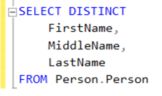

Resim – 5
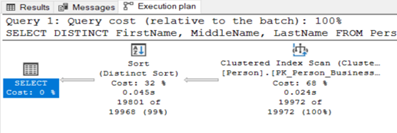

Resim – 6
![]()

Resim – 7
DISTINCT kullanmak yerine sorgumuza BusinessEntityID’yi ekleyerek yine benzersiz satırlar edebiliriz. Bu şekilde sıralama maliyetinden kurtulmuş oluruz ve Execution Time’ları karşılaştırdığımızda daha hızlı bir sorgu elde ettiğimizi görebiliriz.


Resim – 8
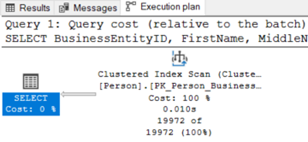

Resim – 9
![]()

Resim – 10
COUNT vs. EXISTS
SQL Server’da belirli bir kaydın var olup olmadığını anlamanın yollarından biri COUNT kullanımıdır. Fakat tablonun uygun bir nonclustered index’i yoksa COUNT, tablonun tamamını okumaya ihtiyaç duyar ve koşulumuzu sağlayan bütün kayıtları sayar. Bu durumda COUNT yerine EXISTS kullanmak bize performans artışı sağlayacaktır. Çünkü EXISTS istenen sonucu bulduğu an döngüden çıkar yani tüm tabloyu taramaya ihtiyaç duymaz.
Bunu basit bir örnek ile açıklamak gerekirse SalesOrderDetails tablosu için aşağıdaki sorguyu çalıştırıp sonuçları inceleyelim.
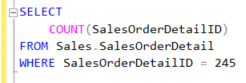

Resim – 11


Resim – 12

Resim – 13
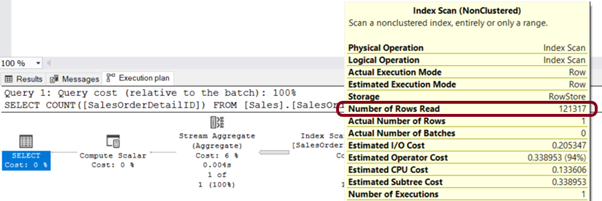
Execution Plan’da Index Scan yapıldığını yani tüm tablonun okunduğunu görebilmekteyiz. Şimdi, bu sorguyu EXISTS ile yeniden yazıp sonuçları karşılaştıralım.


Resim – 14


Resim – 15
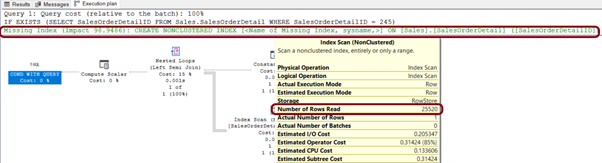
İstatistiklere baktığımızda logical reads’in 276’dan 60’a kadar düştüğünü görebilmekteyiz.

Resim – 16
Execution Plan’a baktığımızda ise okunan satır sayında azalma olduğunu görebiliyoruz. Ayrıca Execution Plan’ın bize önerdiği nonclustered index’i tabloya ekleyerek sorguyu daha da iyileştirebiliriz.
LIKE VE WILDCARD KULLANIMI
Kayıtlar arasında arama yapmak için kullandığımız LIKE operatörü ve wildcard karakterleri bazı kullanımlarda performans düşüşlerine sebep olabilmektedir.
% karakterini string başında kullanmak, uygun index’e sahip olsak bile sistemin full table scan yapmasına neden olacaktır.
Örnek olarak;


Resim – 17
Eğer biz noktada “And” ile başlayan isimleri filtrelemeyi hedefliyorsak bu sorgu bizim için verimsiz olacaktır. Çünkü, bu sorgu bize isim alanının herhangi bir yerinde “And” geçen bütün kayıtları getirir.
İhtiyaç duymadığımız kayıtları elemek için her zaman olabildiğince en kısıtlı filtremeyi yapmalıyız.

Resim – 18
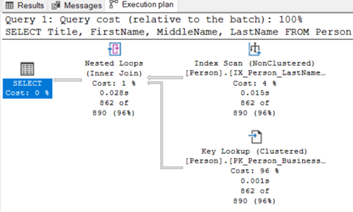

Resim – 19
Execution Plan’a baktığımızda yukarıda bahsettiğim gibi Index Scan yapıldığını yani bütün tablonun okunduğunu görebiliriz.
Şimdi bu sorguyu daha verimli hale getirebilmek için aşağıdaki şekilde yeniden çalıştıralım.

Resim – 20
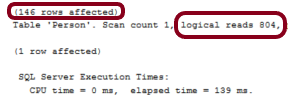

Resim – 21
İstatistiklerde daha az kayıt çektiğimizi ve logical reads’in azaldığını görebilmekteyiz.
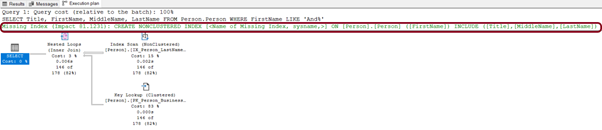

Resim – 22
Execution Plan’ı incelediğimizde ise ilk örnekle benzer olduğunu düşünebiliriz fakat wildcard’ı sadece string’in sonunda kullandığımızda bize eksik olan bir index’i önerdi. Bu index’i ekleyerek sorgumuzu daha performanslı hale getirebiliriz.
UNION vs. UNION ALL
UNION ve UNION ALL operatörlerini iki veya daha fazla SELECT sorgusunun sonuç kümelerini birleştirmek için kullanırız. İki operatörün birbirinden ayrıldıkları nokta; UNION ALL’ın tüm kayıtları döndürmesi, UNION’un ise tekrarlı kayıtları ortadan kaldırması yani bir DISTINCT maliyeti oluşturmasıdır. Bu da özellikle büyük tablolarda performans sorunlarına neden olabilmektedir.
Sonuç kümeleri benzer kayıtlar içeriyorsa UNION’a alternatif olarak UNION ALL kullanmadan önce daha fazla benzersiz sütün ekleyerek tekrarlı kayıtları kaldırabiliriz.
Eğer sonuç kümelerimizin farklı kayıtlar döndürdüğünden eminsek UNION yerine UNION ALL kullanmak bize performans artışı sağlayacaktır.
Örnek olarak aşağıdaki sorguyu inceleyelim.
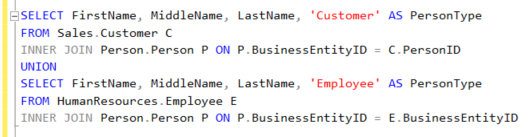

Resim – 23
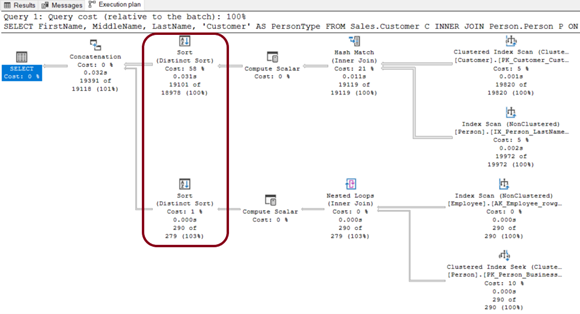
Resim – 24
![]()

Resim – 25
Execution Plan’da DISTINCT maliyeti olduğunu görmekteyiz. Şimdi UNION ALL ile performans artışı sağlamayı deneyelim.


Resim – 26
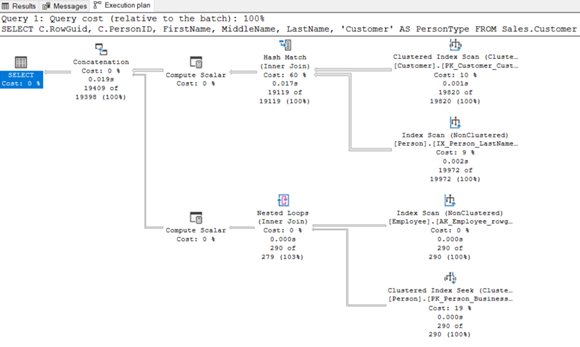

Resim – 27
![]()

Resim – 28
Sonuçları incelediğimizde DISTINCT maliyetinden kurtulduğumuzu ve logical reads’te azalma olduğunu görebilmekteyiz.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar:
https://dataschool.com/how-to-teach-people-sql/difference-between-where-and-on-in-sql/
https://webbtechsolutions.com/2009/07/24/the-effects-of-distinct-in-a-sql-query/
https://www.brentozar.com/archive/2010/06/sargable-why-string-is-slow/