

Microsoft Azure Machine Learning Studio ile Makine Öğrenmesine Giriş serisinden herkese selamlar. Bu bölümde, basit bir doğrusal regresyon uygulaması geliştireceğiz. Eğer serinin ilk yazısını okumadıysanız, aşağıdaki bağlantıdan ulaşabilirsiniz.
Azure Machine Learning Studio ile Makine Öğrenmesine Giriş #01
Doğrusal Regresyon Nedir?
Uygulamamızı geliştirmeye başlamadan önce, ilk olarak kullanacağımız yöntemi tanımlayalım. Doğrusal Regresyon, en basit anlamda iki değişken arasındaki ilişkiyi tanımlayan bir istatiksel yöntemdir. Bir başka deyişle, doğrusal regresyon, modellerde kullanılan bağımlı veya bağımsız değişkenlerin birbirlerini ne ölçüde etkilediğini inceler. Örnek olarak; bir çalışanın, tecrübesi ile o çalışanın maaşı arasında bir ilişki kurmak istediğimizde, çalışanın tecrübesini, bağımsız değişken ve çalışanın maaşını, bağımlı değişken olarak tanımlayabiliriz. Bu durumda doğrusal regresyon, bağımsız değişkenin değerlerini baz alarak, bağımlı değişkenin alabileceği değerleri tahmin eder. Yani, çalışanın tecrübesi ile maaşı arasındaki ilişkiyi matematiksel olarak açıklar. Daha akılda kalıcı olması için aşağıdaki grafikle durumu özetleyebiliriz. (Resim-1)
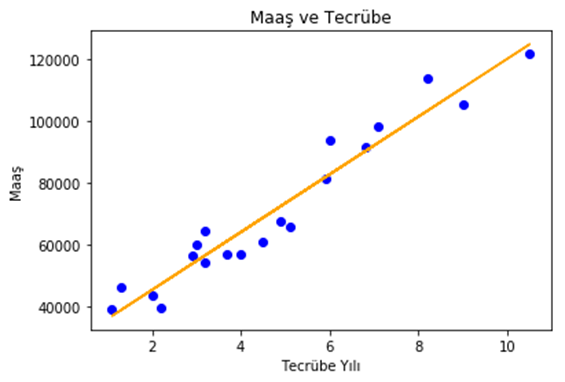

Resim-1
Paket Oluşturma
Bildiğiniz üzere Azure Machine Learning Studio’da çalışma paketlerini Experiments (deneyler) başlığı altında oluşturuyoruz. Yeni bir paket oluşturmak için, ilk olarak ekranın en altında yer alan bölümdeki New butonuna tıklıyoruz. Açılan ekranda Experiments sekmesine geliyoruz. Burada Microsoft’un bize sunmuş olduğu birçok taslak paket bulunmaktadır. İleri ki bölümlerde bu hazır taslakları da inceleyeceğiz ancak bu bölümde doğrusal regresyon çalışmasına odaklanacağımız için, paket içeriğini de sıfırdan oluşturacağız. Bu yüzden Empty seçeneğini seçerek çalışma ortamımızı oluşturuyoruz. (Resim-2)
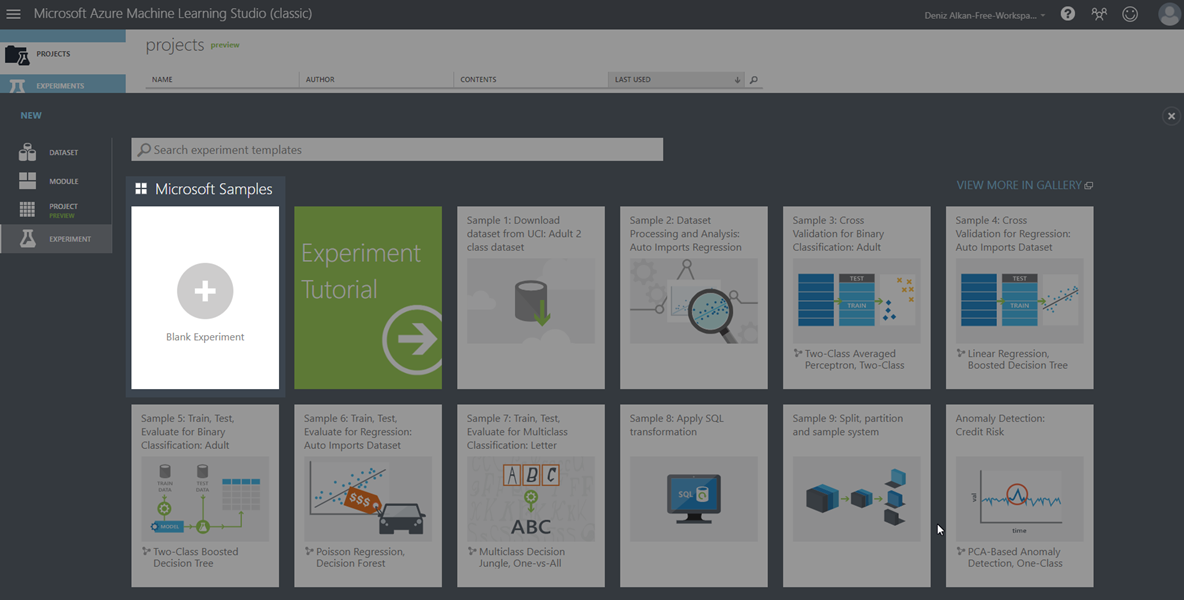

Resim-2
Paketimizi oluşturduktan sonra, ekranın solunda yer alan bileşenleri kullanarak akışımızı oluşturmaya başlayacağız. İlk olarak bize bir veri kaynağı gerekli. Bu amaçla, Microsoft’un sağlamış olduğu hazır veri setlerini kullanabileceğiniz gibi, bilgisayarınızda yer alan herhangi bir CSV dosyasını da veri kaynağı olarak sisteme ekleyebilirsiniz. Biz bu örneğimizde Microsoft’un sağlamış olduğu hazır veri setlerinden bir tanesini kullanacağız. Haydi başlayalım.
İlk adım olarak, ekranın sol tarafında yer alan menüden, Saved Datasets başlığı altındaki Automobile Price Data (Raw) isimli veri setini, çalışma alanına taşıyoruz. (İster çift tıklayarak, isterseniz sürükleyip bırakarak taşıyabilirsiniz. (Resim-3)

Resim-3
Veriyi Tanıma
Veri setini çalışma alanına ekledikten sonra, sağ tık yapıp, Dataset menüsü altındaki Visualize seçeneğini seçiyoruz. Bu ekranda, veri seti hakkında hızlıca fikir sahibi olabilmeniz için, görsel bir özet yer alıyor. Açılan pencerenin sol üst köşesinde, veri setindeki satır ve sütun sayısını görebiliriz. Orta kısımda ise veri setinin içeriğini görebiliyoruz. Bu tablo yapısında, herhangi bir kolonun üzerine tıkladığınızda, pencerenin en sağ tarafında, seçilen kolonun istatistiksel ve grafiksel olarak özet bilgileri yer alıyor. Statistics sekmesi altında, seçilen kolon içerisinde benzersiz değerlerin kaç adet olduğu (Unique Values), kaç adet satırda boş değer olduğu (Missing Values) veya kolonun veri tipinin ne olduğu (Feature Type) gibi bilgilere ulaşabilirsiniz. Visualizations sekmesi altında ise, kolondaki değerlerin adet dağılımı yer almakta. (Resim-4)
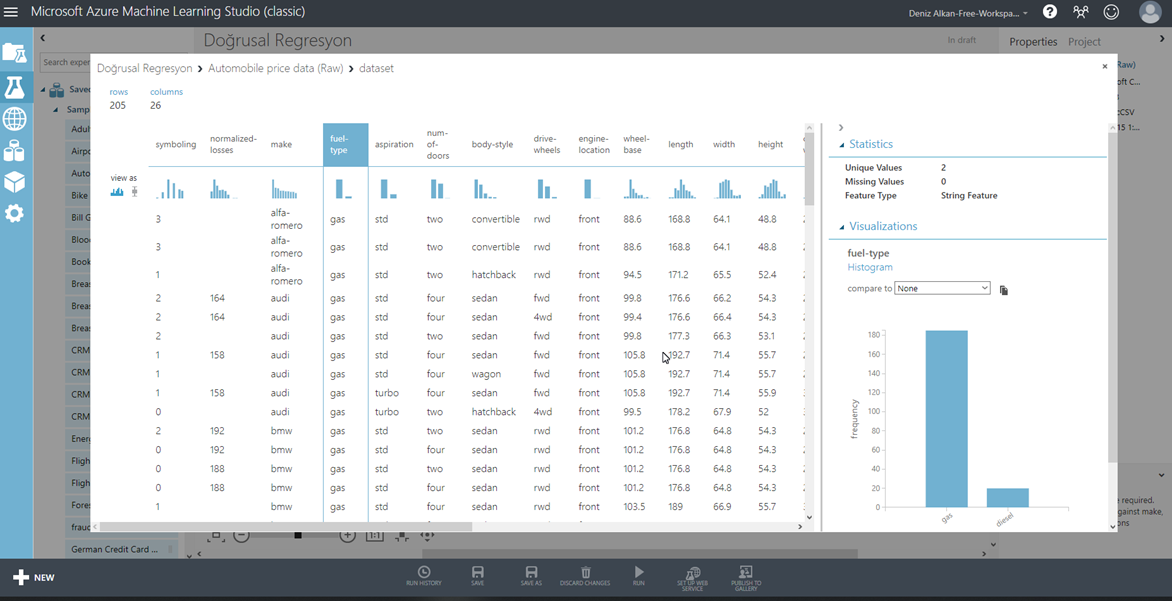

Resim-4
Kolon Seçme
Veri setine göz attıktan sonra, geliştireceğimiz model için bize hangi kolonların gerektiğine karar vermek gerekiyor. Veri setindeki tüm kolonlar işimize yaramıyor olabilir, bu yüzden modelimizde kullanacağımız verileri seçmek için sol menüdeki arama kısmına Select Columns in Dataset yazarak ihtiyacımız olan bileşeni çalışma alanına sürüklüyoruz. Daha sonrasında veri setimizle bu bileşeni birleştiriyoruz. Modelimizde kullanacağımız kolonları seçmek için, Select Columns in Dataset bileşeninin üzerine bir kere tıkladıktan sonra, ekranın sağındaki sekmeden Launch Column Selector butonuna tıklıyoruz. (Resim-5)
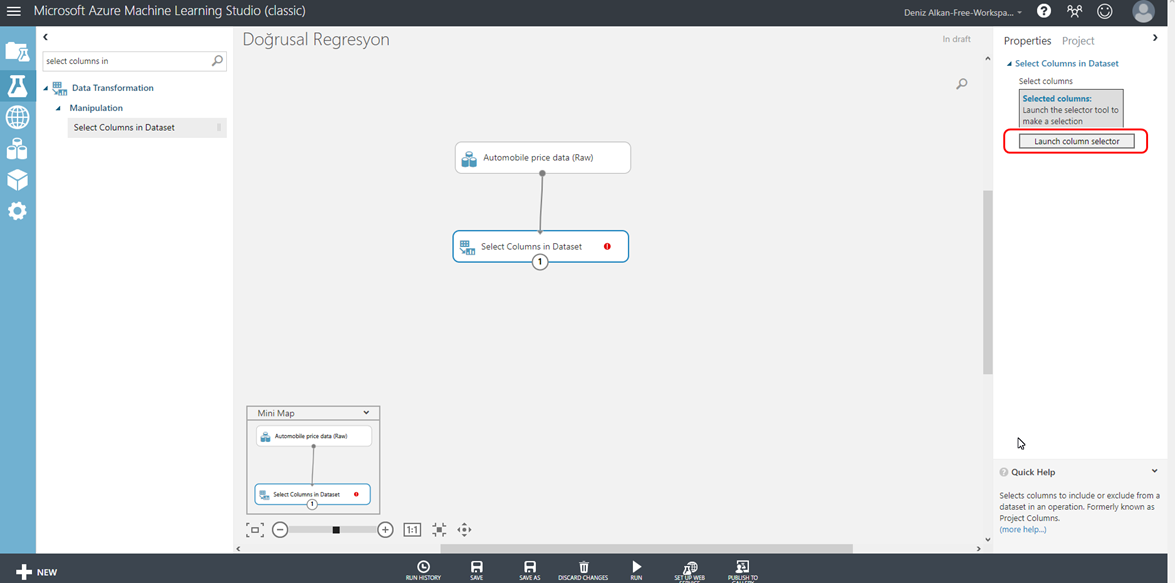

Resim-5
Açılan pencere, iki farklı şekilde kolon seçimi yapabiliyoruz. By Name (isme göre) sekmesinde, direkt olarak isimler üzerinden istediğimiz kolonları seçebiliyoruz. With Rules (kural ile) sekmesinde ise, belirli kurallar tanımlayarak, bir veya birden fazla kolonu seçebiliyoruz.
Bizim geliştireceğimiz uygulamaya geri dönecek olursak, biz bu veri setindeki, Normalized-losses kolonu dışındaki tüm kolonları kullanacağız. Neden bu kolonu devre dışı bırakıyoruz, çünkü diğer tüm kolonlarda doluluk oranı yüksek. Ancak bu kolondaki verilerin 41 tanesi boş değer içeriyor. (Bu bilgiyi veri setinin özetini incelerken öğrendik.) Veri setindeki toplam satır sayısının da 205 olduğunu ele alırsak, bu kolondaki veriler neredeyse %20 oranında boş. Bu da kullanacağımız doğrusal regresyon algoritmasını olumsuz yönde etkiliyor. Bu yüzden modelimizi daha verimli bir veri seti ile çalıştırabilmek için Normalized-losses kolonu devre dışı bırakıyoruz. Bunun içinde With Rules sekmesinde gerekli seçimleri yaparak, pencerenin sağ alt köşesinde yer alan onay işaretine tıklıyoruz. (Resim-6)
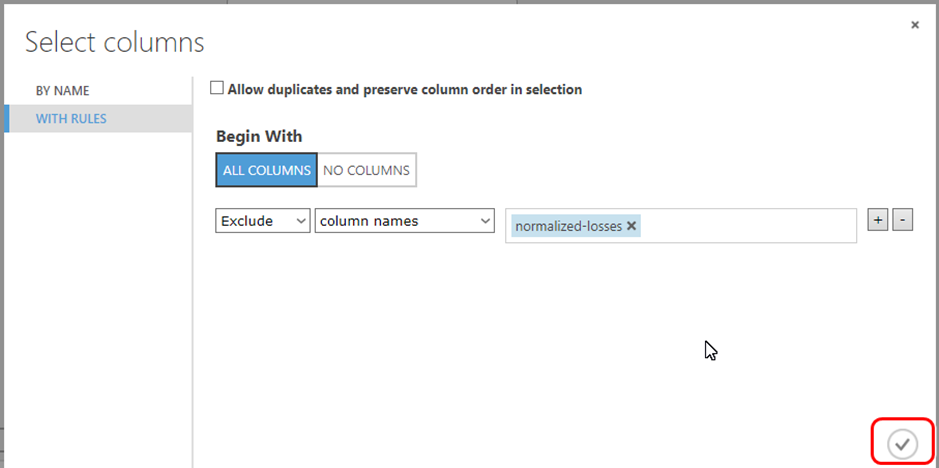

Resim-6
Veri Temizleme
Kullanacağımız kolonları seçtikten sonra, modelimizin daha iyi çalışması için, elimizdeki verinin kalitesini arttırmaya yönelik bir çalışma yapacağız. Veri temizleme olarak adlandırdığımız bu aşamada, eksik verileri temizleme ve aykırı değerleri tespit etme gibi işlemler yaparak, modelimizi olumsuz yönde etkileyecek her türlü durumu düzeltmeye çalışacağız. Veri temizleme aşamasına başlamak için ilk olarak, sol taraftaki menüden, Clean Missing Data bileşenini çalışma alanımıza ekliyoruz. Bir önceki Select Column in Dataset bileşeni ile birleştiriyoruz. (Resim-7)
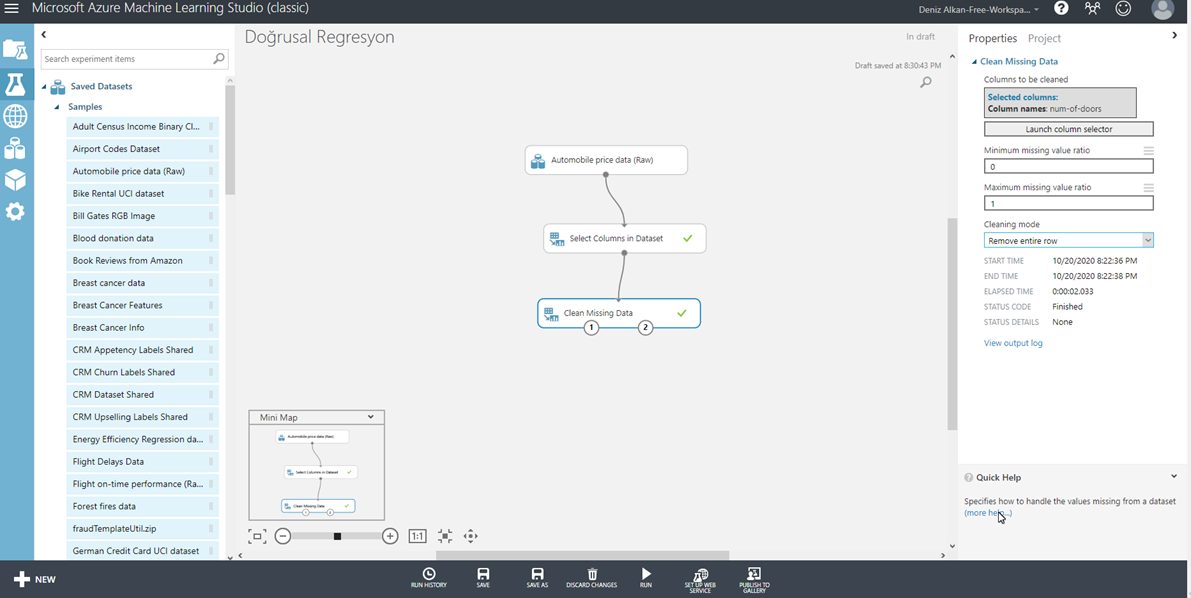

Resim-7
Bileşeni ekledikten sonra, ekranın sağındaki Properties sekmesinde veriyi nasıl temizleyeceğimizle ilgili seçenekler çıkıyor. Bir önceki aşamadaki gibi, Launch Column Selector butonuna bastıktan sonra, temizlemek istediğimiz kolonu seçiyoruz. Kolon seçim ekranını kapattıktan sonra, Properties sekmesindeki Cleaning Mode bölümünden, hangi yöntemle eksik verileri düzelteceğimizi seçiyoruz. Buradaki seçeneklerden birkaçını açıklamak gerekirse;
- Custom Subsitution Value: Kolondaki eksik verilerin tamamını, belirttiğiniz bir değer ile değiştirir.
- Replace with Mean: Eksik verileri o kolondaki değerlerin ortalamasıyla doldurur.
- Remove Entire Row: Eksik değer içeren satırı siler.
Seçenekleri açıkladıktan sonra, tekrar bizim akışımıza dönecek olursak, biz bu aşamada Num-of-doors kolonunu seçiyoruz. Bu kolonda arabaların kaç kapılı olduğu bilgisi bulunuyor. Kolondaki 2 değerin eksik olduğunu görüyoruz. Bu durumda fazla bir kaybımız olmayacağı için Remove Entire Row seçeneğini seçerek, eksik değer için satırları veri setimizden çıkarıyoruz. Yaptığımız seçimlerin veri setine etki etmesi için ekranın en altında yer alan bölümden Run butonuna tıklıyoruz. Böylece şu ana kadar oluşturduğumuz akışı çalıştırmış oluyoruz. Akışı çalıştırdıktan sonra Clean Missing Data bileşenine sağ tık yapıp sırasıyla, Cleaned Dataset ve Visualize seçeneğini seçtiğimizde, son durumda elimizdeki verinin özetine ulaşmış oluyoruz. Hatırlarsanız veri setini ilk kez akışımıza eklediğimizde de böyle bir çalışma yapmıştık ve veri setinin 205 satırdan oluştuğunu görmüştük. Şimdi temizlenen verinin özetine baktığınızda 203 satır veri kaldığını göreceksiniz.
Veriyi Bölme
Veri temizleme aşamalarını da geçtikten sonra artık verimiz kullanıma hazır hale geliyor. Bu noktada, verinin bir kısmını modelimizi eğitmek, bir kısmını ise modeli test etmek amacıyla ikiye ayırmamız gerekiyor. Bu ayrım genelde 70’e 30 veya 80’e 20 oranında yapılıyor. Bu oran modelinize ve veri setinize bağlı olarak değişebilir. Biz bu çalışmamızda verimizin %80’lik kısmını modelimizi eğitmek üzere ayıracağız. Kalan %20 ile de test edeceğiz. Veri ayırma işlemi için Split Data isimli bileşeni kullanacağız. Hemen ekranın solundaki menüden aratarak Split Data bileşenini akışımıza dahil edelim. (Resim-8)
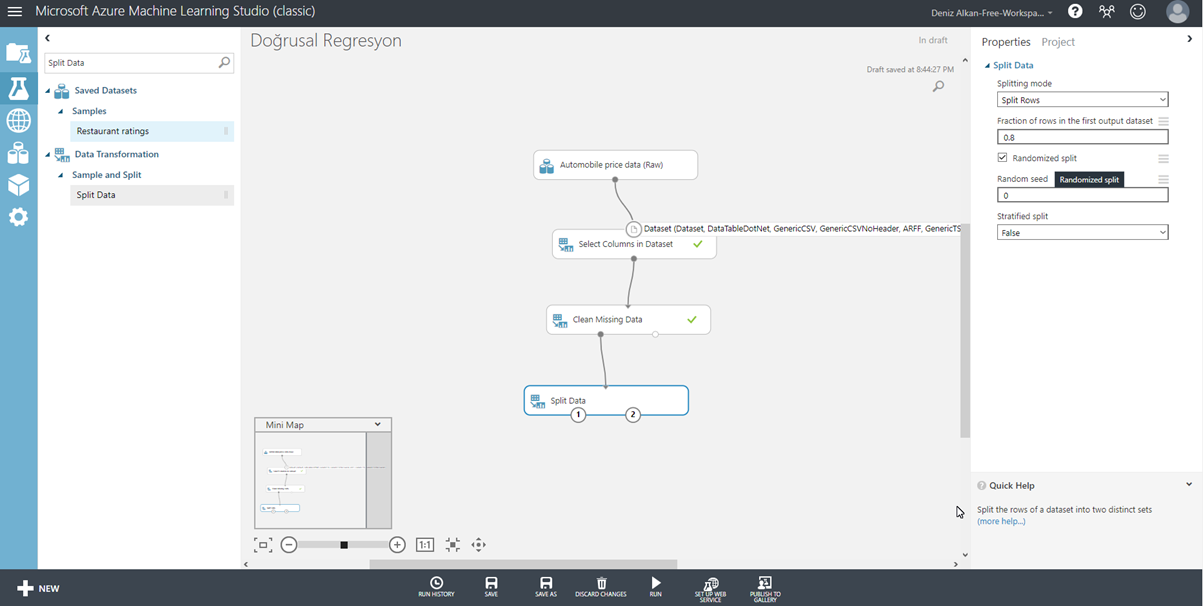

Resim-8
Diğer bileşenlerde olduğu gibi, bileşeni akışa dahil ettikten sonra, ekranın sağındaki sekmeden gerekli seçimleri yapıyoruz ve tekrar yaptığımız seçimlerin çalışması için Run butonuna basıyoruz. Dilerseniz bu aşamada, Split Data bileşenine sağ tıklayıp Run Selected seçeneğine tıklayarak, sadece yeni eklediğimiz bileşeni çalıştırabilirsiniz. Seçimi yaptıktan sonra bileşenin birinci çıkışından %80, ikinci çıkışından %20 oranında veri akışı olacak.
Modeli Eğitme
Veri bölme işlemini de tamamladıktan sonra artık modelimizi eğitme aşamasına geçebiliriz. Bu çalışmamızda Doğrusal Regresyon algoritmasını kullanarak modelimizi eğiteceğiz. Bunun için sol taraftaki menüden, Linear Regression ve Train Model bileşenlerini akışımıza ekliyoruz. (Resim-9)
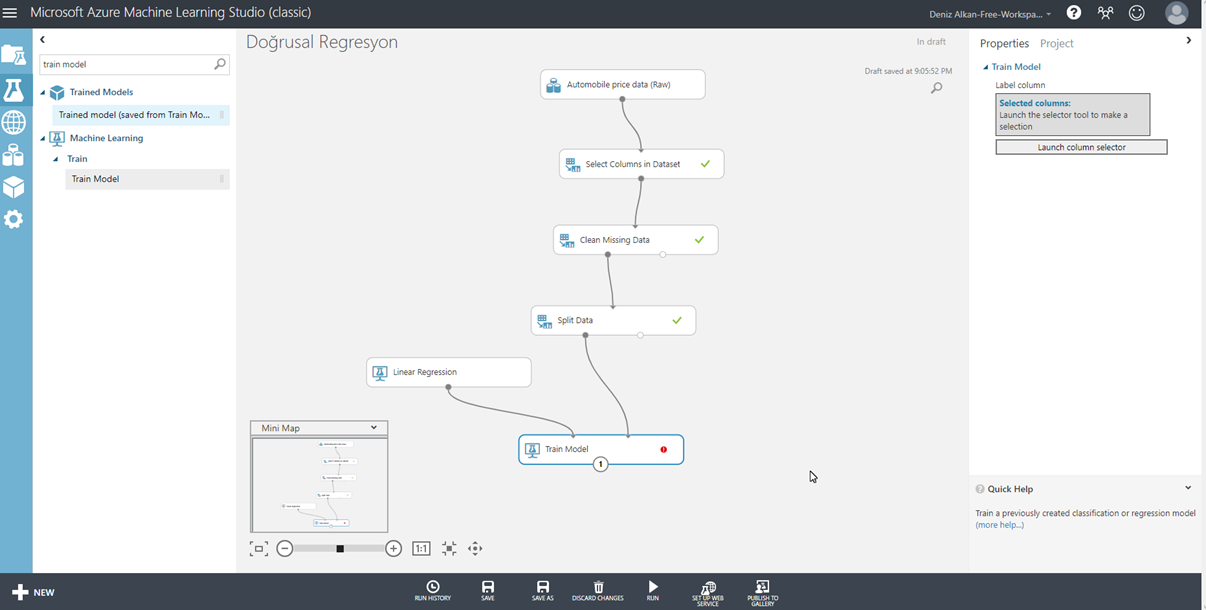

Resim-9
Bileşenlerimiz arasında gerekli bağlantıları kurduktan sonra, ekranın sağındaki sekmeden Launch Column Selector butonuna tıklıyoruz. Burada, tahmin etmek istediğimiz alanı seçiyoruz. Bu senaryoda biz fiyat bilgisini tahmin etmeye çalışacağız. Bu yüzden Price kolonunu seçiyoruz. Bu aşamadan itibaren, akışımızı çalıştırdığımız zaman, doğrusal regresyon algoritmasını kullanarak, verilerimizin %80’i ile modelimizi eğitmiş olacağız. Bir sonraki aşama, modelimizin yaptığı tahminler ile, test için ayırdığımız %20’lik veriyi karşılaştırmak olacak. Bunun için sol taraftaki menüden, Score Model bileşenini akışımıza ekliyoruz. (Resim-10)
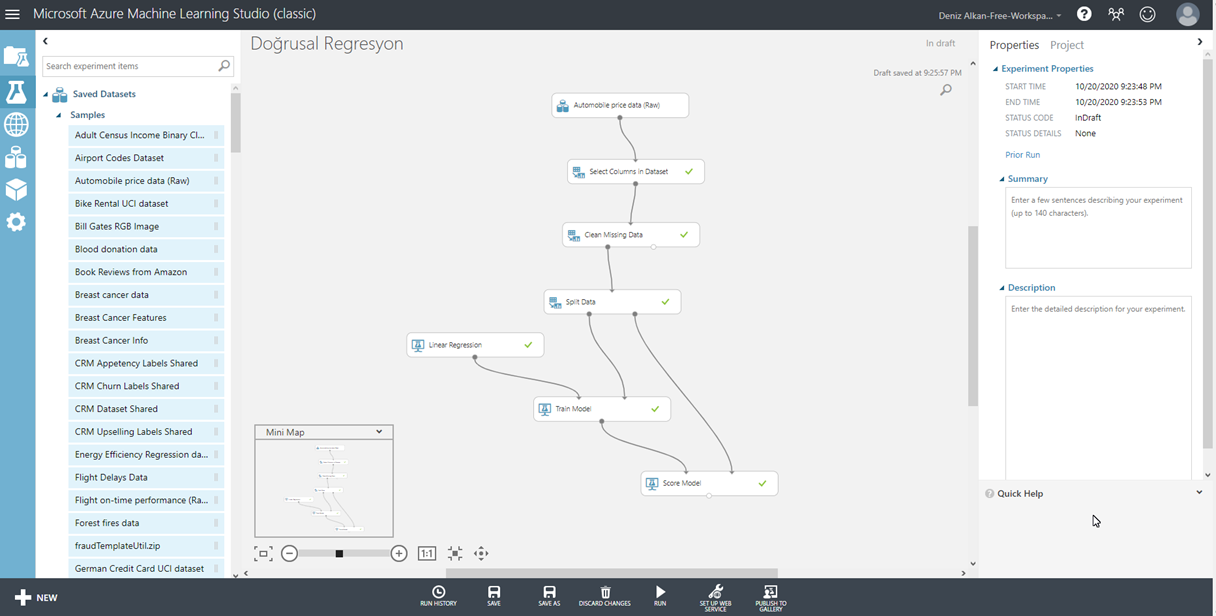

Resim-10
Score Model bileşenini ekledikten sonra akışımızı tekrar çalıştırıyoruz ve Score Model bileşenine sağ tıklayıp, Scored Dataset ve Visualize seçeneklerine tıklıyoruz. Açılan ekranda, %20 oranında ayırdığımız test verisinin yer aldığını görebilirsiniz. Bu tablonun en son kolonunda, modelimizin tahmin ettiği kolonun değerleri yer almakta. (Resim-11)
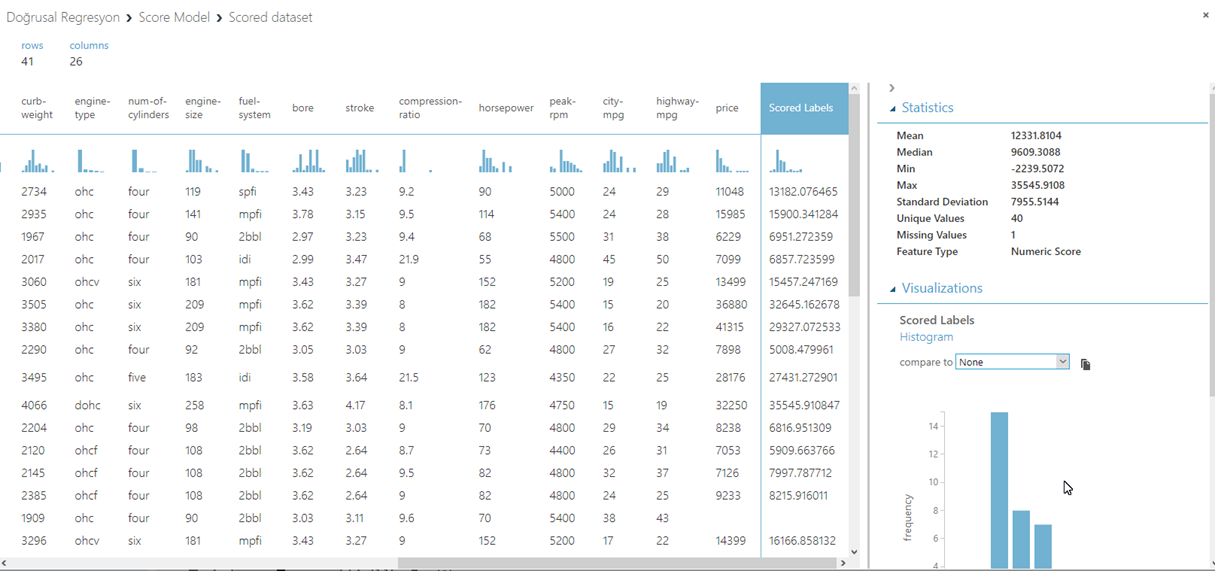

Resim-11
Burada, tahmin ettiğimiz değerlerin gerçek değerler ile kıyaslamasını yapabilirsiniz. Örnek olarak, ilk satırda fiyatı 11.048 olan aracın değerini 13.182 şeklinde tahmin etmiş modelimiz. Aynı şekilde bir alt satırda, 15.985 olan değeri 15.900 olarak tahmin etmiş durumdayız. Bu tahminlerin ne kadar başarılı olup olmadığını ölçmek için, sol taraftaki menüden Evaluate Model bileşenini ekliyoruz ve Score Model ile birleştiriyoruz. Akışımızı tekrar çalıştırdıktan sonra, Evaluate Model bileşenine sağ tıklayıp, Evalutaion Result ve Vizualize seçeneklerine tıklıyoruz. Açılan pencerede yapılan tahminlerin ne oranda hatalı olduğunu görebilirsiniz.
Bu aşamayla birlikte, Azure Machine Learning Studio ortamında, doğrusal regresyon algoritmasını kullanarak basit bir uygulama geliştirmiş olduk. Serinin devamında, farklı algoritmaları kullanarak daha karmaşık projeleri ele alacağız. Sonraki yazılarda görüşmek üzere.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar:
www.mshowto.org
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
https://codingsight.com/creating-simple-linear-regression-azure-machine-learning/
https://medium.com/ml-course-microsoft-udacity/linear-regression-in-azure-ml-studio-8b69a2f7fb80